
决策树
编辑基础介绍
决策树是一种用于做出判断的结构,就像一棵 "树" 一样,从一个问题出发,一步步根据条件分支,最终得出一个决定。在机器学习中,决策树是用来预测的模型,它通过对数据特征的判断,来决定最终的输出结果。
我们可以把决策树看作是多个 if-else 规则的组合。每个节点表示一个问题,每条分支对应一种答案,从根节点出发,不断根据答案选择路径,直到叶子节点,也就是最终的判断结果。决策树可以是二叉的(每个节点两个分支),也可以是多叉的。
决策树的特别之处在于,它非常直观、易于理解。它把从数据中学到的 "知识" 结构化成一层层的判断,即便是不懂技术的人,也可以通过图形快速看懂模型是如何做出决策的。
决策树的优点:
构建过程简单,容易理解,可视化,逻辑清晰
可用于分类和回归任务,且支持多分类
能同时处理数值型和分类型的特征
决策树的缺点:
容易过拟合,尤其在训练数据复杂时,树结构可能非常庞大。可以通过 "剪枝" 方法缓解,比如限制树的最大深度或叶子节点的最小样本数。
构造一棵最优的决策树是个 NP-完全问题,现实中通常采用贪心策略,即每一步选择当前最优分裂点。这种方法不能保证最终树结构是全局最优的。不过,像随机森林这样的方法可以通过引入随机性来改善这个问题。
一个简单的例子:
假设有人给你介绍对象,你会根据对方是否 "白、富、美" 来决定要不要去相亲。我们把所有可能组合列出来,并记录你的决定,比如:
我们可以把这个判断过程画成一棵树。比如,先问 "白不白" ,接着问 "富不富" ,最后问 "美不美" 。每一层都提出一个问题,根据答案继续往下,直到得出决定。
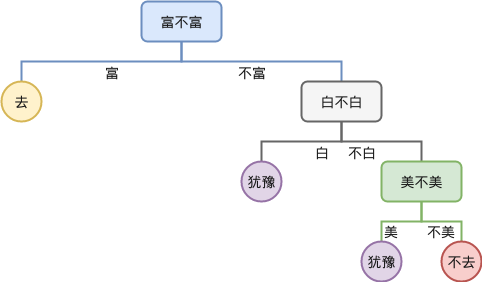
这就是决策树的基本形式。不同的判断顺序会形成不同的树结构,比如如果先问 "富不富" ,再问 "白不白" ,树形就会不同。
不同决策树的对比:
通过观察不同决策顺序构成的树,我们会发现有些叶子节点可以合并。比如当多个分支结果相同时,我们就可以提前做出判断,不再继续往下分裂,这样可以简化树结构。
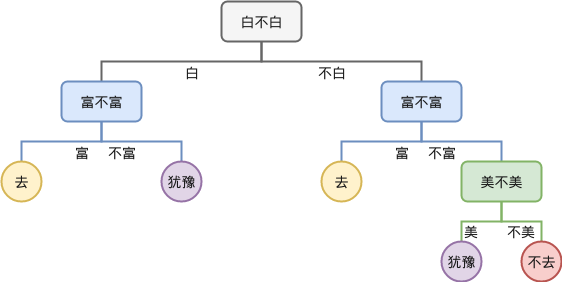
例如, "白→富→美" 的顺序构成的树,合并后可能有5个叶子节点;而 "富→白→美" 的树合并后可能只剩4个叶子节点。叶子节点越少,往往表示模型越简洁,泛化能力也越好。因此,构建决策树的一个目标就是在保证判断准确的前提下,尽可能减少叶子节点的数量。
决策树分类算法:
基于 ID3 的决策分析
ID3 是由 J.Ross Quinlan 在 1986 年提出的一种基于决策树的分类算法。该算法以信息论为基础,通过衡量 "信息熵" 和 "信息增益" 来对数据进行分类。ID3 使用的是一种自顶向下的贪心策略,每一步都选择信息增益最大的特征进行划分。这样构建出的决策树通常结构较小,查询速度较快。
ID3 的一个核心思想基础是 "奥卡姆剃刀原则" ——在能准确分类的前提下,越简单的模型越好。因此,ID3 倾向于生成结构更精简的树。然而,需要注意的是,它构造出的树并不一定是最优的或最小的。
信息量
信息量可以理解为我们从一个事件中获得的 "惊讶程度" 或 "新鲜感" 。比如:
事件 A:巴西队进入 2018 世界杯决赛圈。
事件 B:中国队进入 2018 世界杯决赛圈。
显然,B 能惊死人。一般来说,事件发生的概率越低,带来的信息量越大;反之,概率越高的信息带来的价值就越小。
信息量和事件发生的概率有关,概率越小,信息量越大;
信息量总是非负的,必然发生的事件信息量为 0;
两个互不相关的事件,它们的信息量是可以相加的。
信息量的计算公式为:
其中底数a 的选择会影响单位:
以 2 为底,单位是 bit;
以e 为底,单位是 nat;
以 10 为底,单位是 dit。
举个例子:
下雨概率为 0.5,那么信息量为- \log_2 0.5 = 1 bit;
飞机在下雨天正常起飞的概率是 0.25,则信息量为- \log_2 0.25 = 2 bit。
信息熵
信息熵(Entropy)指的是 "平均信息量" ,可以理解为我们对一个系统中不确定性的总体评估。信息越杂乱,熵越大;信息越清晰,熵越小。
假设有一个随机变量X ,它可以取n 个不同的值x_1, x_2, ..., x_n ,对应的概率分别为p_1, p_2, ..., p_n ,那么X 的信息熵为:
条件熵
在构建决策树时,我们会根据某个特征来划分样本。此时我们关心的是,在已知某个条件下(比如样本被分到某一类),系统还有多少不确定性,这就是 "条件熵" 。条件熵反映的就是切分后整体的平均熵。
如果Y 是划分数据的某个特征,那么X 在给定Y 的条件下的熵是:
可以理解为,用特征Y 进行划分后,每个子集都有自己的信息熵,条件熵就是这些子集信息熵的加权平均。
信息增益
信息熵反映的是系统的 "不确定性" ,当一个系统越难预测,其信息熵就越高,尤其在数据均匀分布的情况下,熵达到最大值。
在决策树中,如果用某个特征对数据进行分类,通常可以减少整体的不确定性,也就是降低信息熵。分类前后的信息熵差值,就称为信息增益,它用来衡量一个特征在分类时的有效性。信息增益越大,说明这个特征越能有效地划分数据。
具体来说,假设我们有一个离散特征a ,它有V 个不同的取值a_1, a_2, ..., a_V 。用这个特征对样本集D 进行划分后,会得到V 个子集,分别记为D_1, D_2, ..., D_V 。那么,特征a 带来的信息增益可以表示为:
这个公式的含义是:原始样本集D 的信息熵H(D) ,减去用特征a 划分后各个子集的信息熵的加权平均。其中,\frac{|D_v|}{|D|} 是第v 个子集在总样本中的占比,也就是它的 "权重" 。由于每个子集所包含的样本数量不同,它们对总信息熵的影响也不同,因此需要加权计算。
简而言之,信息增益就是通过某个特征进行划分后,样本整体 "混乱程度" 降低了多少。这个数值越大,说明这个特征越有助于分类,也就越值得在构建决策树时优先使用。
ID3 算法流程
输入:数据集D ,特征集A 输出:一棵 ID3 决策树
计算当前数据集中所有特征对应的信息增益;
选择信息增益最大的特征,作为当前节点的划分依据(即测试属性);
根据该特征的不同取值,将数据集划分为若干个子集;
对于每个子集:
如果子集中所有样本都属于同一类别,则将该分支标记为叶子节点,并赋予对应的类别标签;
否则,递归调用 ID3 算法,在该子集上继续构建子树。
如此重复,直到所有特征用尽,或所有样本均已被正确分类,最终生成一棵完整的决策树。
ID3 算法的应用
我们通过一个实际案例,来更直观地了解 ID3 算法的完整执行过程。
下表是一个学生考试相关的数据集,包含三个特征:考试成绩、作业完成情况和出勤率,目标是判断学生是否能够通过考试。
1. 计算原始数据集的信息熵
目标变量是 "是否能通过考试" ,共有 10 条记录,其中 7 个为 "是" ,3 个为 "否" 。
根据信息熵公式:
2. 计算每个特征的信息增益
设特征A_1 表示 "考试成绩" ,A_2 表示 "作业完成情况" ,A_3 表示 "出勤率" 。
(1)特征A_1 (考试成绩):
该特征有四种取值(优、良、及格、不及格),样本按此划分后,信息增益计算如下:
其中:
D_1 (优)全部为 "是" ,熵为 0;
D_2 (良)全部为 "是" ,熵为 0;
D_3 (及格)有 3 个 "是" ,1 个 "否" :
H(D_3) = -\frac{3}{4} \log_2 \frac{3}{4} - \frac{1}{4} \log_2 \frac{1}{4} = 0.811D_4 (不及格)全部为 "否" ,熵为 0。
代入公式:
(2)特征A_2 (作业完成情况):
类似计算可得:
(3)特征A_3 (出勤率):
该特征只有两个取值(高、低),划分后两个子集分别为:
出勤率为 "高" :7 个样本,7 个 "是" ,信息熵为 0。
出勤率为 "低" :3 个样本,全为 "否" ,信息熵为 0。
因此信息增益为:
3. 选择最优特征并继续划分
比较各个特征的信息增益:
Gain(D, A_1) = 0.539
Gain(D, A_2) = 0.406
Gain(D, A_3) = 0.881
因此,选取A_3 (出勤率)作为当前最优划分特征。
接下来,根据考试成绩将数据分为四个子集,然后对每个子集递归执行 ID3 算法,并继续在剩余的特征(作业完成情况、出勤率)上进行划分,直到所有样本属于同一类,或特征集为空。
ID3 算法的优缺点
优点:
ID3 算法逻辑清晰,流程简单
决策树本身是一种类似 "流程图" 的结构,生成的模型便于可视化,易于理解和解释
可以应用于各种离散型特征的数据集,并根据实际需求进行裁剪或扩展。
在数据有一定噪声的情况下,依然可以通过统计特征的整体分布做出相对稳定的判断。
决策树始终能构建完成,避免了某些算法 "无解" 或 "收敛失败" 的问题。
缺点:
信息增益在计算时对取值多的特征偏好明显,可能导致选择那些虽不重要但取值丰富的特征,进而影响模型准确性。
原始 ID3 算法只适用于离散特征,对于连续属性无法直接处理,需要进行预处理或离散化。
ID3 无法处理样本中存在缺失值的情况,往往需要在数据预处理阶段进行填补或剔除。
在训练数据中表现很好,但可能在新数据上泛化能力差。尤其在样本较少、特征较多时更容易产生过拟合现象。
ID3 使用贪心策略,每一步只考虑当前最优划分,无法保证整个决策树达到全局最优。这种 "局部最优" 的策略是很多决策树算法的通病。
基于 C4.5 算法的分类决策树
C4.5 是由 J. Ross Quinlan 在 ID3 算法的基础上提出的改进版分类算法。它不仅继承了 ID3 算法结构清晰、易于实现的优点,还在多个关键点上进行了优化,使得生成的分类规则更加准确、可解释性更强。
不过,C4.5 也存在一定的局限性: 它的计算效率相对较低,通常只适用于可以完全加载进内存的小型或中型数据集。
C4.5 相比 ID3 的主要改进
使用信息增益率(Gain Ratio)代替信息增益作为划分标准: 解决了 ID3 中 "偏向取值多的特征" 的问题。
支持剪枝操作: 在构建决策树的过程中加入剪枝策略,有效避免过拟合,提高泛化能力。
支持连续属性处理: C4.5 可以自动将连续型特征离散化,扩大了算法的适用范围。
可以处理缺失值: 对于部分缺失的数据样本,C4.5 可以通过概率估计方式继续参与计算,而不需舍弃整条样本。
为什么仅使用信息增益会出问题?
假设有14个样本的数据,增加一列特征 data = [1,2,3,4,5,6,7,8,9,10,11,12,13,14],根据公式,可以算出对应的信息增益为:Gain(D,data) = 0.940, 我们发现,它所对应的信息增益远大于其他特征,所以我们要以data特征,作为第一个节点的划分。这样划分的话,将产生14个分支,每个分支对应只包含一个样本,每个分支节点的纯度已达到最大,也就是说每个分支节点的结果都非常确定。但是,这样的决策树,肯定不是我们想要的,因为它根本不具备任何泛化能力。
为了解决这个问题,C4.5 引入了 信息增益率。
信息增益率
假设我们有一个数据集D ,以及一个特征a ,它可能取值为a_1, a_2, \dots, a_V 。当我们使用特征a 来对数据集进行划分时,其增益率定义如下:
其中,IV(a) 表示特征a 的固有值(也可以理解为它自身的信息熵),计算方式为:
简单来说,IV(a) 就是特征a本身的信息熵,衡量的是特征a 的取值在整个数据集中分布的情况。特征的取值种类越多,IV(a) 往往就越大,进而导致增益率变小。这样可以避免信息增益偏向于取值种类较多的特征。
不过,增益率也容易偏向取值较少的特征。为了解决这个问题,常用的一种 "启发式" 策略是:先从所有候选特征中挑选出信息增益高于平均水平的那些,然后再从中选择增益率最高的特征作为最终的划分依据。
C4.5 算法应用实例
我们继续使用前面提到的例子来说明 C4.5 算法的具体应用过程:
1. 计算原始数据集D 的信息熵:
2. 分别计算按各个属性划分后子集的信息熵:
对属性A_1 划分后的信息熵:
属性A_2 :
属性A_3 :
3. 基于上述信息熵,计算每个属性对应的信息增益:
4. 计算每个属性的 "固有值"H(V) (即划分后的信息分布程度):
对A_1 :
对A_2 :
对A_3 :
5. 最后,计算每个属性的信息增益率(IGR):
综合来看,由于A_3 的信息增益率最高,因此在构建决策树时,优先选择A_3 作为根节点,并以此为依据进行下一步的划分。
基于CART的决策划分
在数据挖掘中,决策树主要分为两类:分类树和回归树。分类树的输出是类别标签,而回归树则输出一个实数。分类与回归树统称为CART(Classification and Regression Tree),由 Breiman 等人提出,是一种典型的决策树方法。CART 算法包括两个主要步骤:
树的生成:根据训练数据构建一棵尽可能完整的树。
剪枝处理:使用验证集对已生成的树进行剪枝,选出最优子树,通常以损失函数最小为准则。
CART 既可以用于分类任务,也可应用于回归问题,其特点主要体现在以下三点:
二叉划分(Binary Split):每次划分都将数据分为两个部分。无论特征有多少取值,CART 都通过 "是/否" 决策,将样本划分成两个子集,因此最终构建的是一棵结构清晰的二叉树。
单变量划分(Split Based on One Variable):每次划分只基于一个变量,选择当前最优的分割方式。
剪枝机制:剪枝是 CART 的核心步骤之一,甚至被认为比树的生成更关键。研究表明,即使初始生成的树结构存在差异,通过合理剪枝后往往能保留最关键的特征划分,从而提升模型效果。
在具体构建过程中,CART 以递归方式生成二叉树。对于回归任务,使用平方误差最小化作为划分准则;对于分类任务,则采用基尼指数(Gini index)进行特征选择。
ID3、C4.5 和 CART 的对比
基尼指数(Gini Index)
基尼指数和信息熵一样,用来衡量数据集的 "混乱程度" 或不确定性。我们可以把它理解为:一个集合越 "纯" ,即样本越集中在同一类,基尼指数就越小;反之,越分散,基尼指数越大。
假设数据集D 中共有K 个类别,样本属于第k 类的概率为p_k ,则D 的基尼指数定义为:
也可以写成根据样本数量的形式,设C_k 是D 中属于第k 类的样本子集,则:
这个值可以理解为:从D 中随机抽取两个样本,它们属于不同类别的概率。因此,基尼指数越小,数据集的 "纯度" 越高。
当我们用某个属性a 来对数据集D 进行划分时,划分后的基尼指数为:
其中D_v 表示属性a 取第v 个值时划分出的子集,V 是a 的所有可能取值。
例如,如果将D 按属性A 的某个值划分成两个子集D_1 和D_2 ,则有:
我们从候选属性集合A 中,选择使划分后基尼指数最小的属性,作为当前最优划分属性:
CART 决策树的划分过程会在以下任一条件满足时停止:
当前节点样本数量小于预设阈值;
当前节点的基尼指数已经足够小(即大多数样本已归于同一类);
没有更多可用的特征可供划分。
应用实例:决策划分(以体温为特征)
我们以 "体温" 为特征,对动物进行分类。根据表格数据,我们将样本划分为两类:
恒温类(D_1 ):包括 7 个样本,其中哺乳类 5 个、鸟类 2 个;
非恒温类(D_2 ):包括 8 个样本,其中爬行类 3 个、鱼类 3 个、两栖类 2 个。
首先,分别计算这两个子集的基尼指数:
恒温类的基尼指数:
Gini(D_1) = 1 - \left[\left(\frac{5}{7}\right)^2 + \left(\frac{2}{7}\right)^2\right] = \frac{20}{49}非恒温类的基尼指数:
Gini(D_2) = 1 - \left[\left(\frac{3}{8}\right)^2 + \left(\frac{3}{8}\right)^2 + \left(\frac{2}{8}\right)^2\right] = \frac{42}{64}
然后,计算 "体温" 特征(记为A_1 )划分下的加权基尼指数(即划分后的总体基尼值):
这个值表示在 "体温" 这一特征的划分下,整个数据集的不确定性程度。我们将对所有候选特征做类似计算,最终选择使Gini\_Gini 最小的特征作为当前最优划分特征。
CART 决策树实例:动物分类(基于基尼指数)
数据集概况
共有 15 个动物样本,每个样本具有以下三个特征:
体温:恒温 / 冷血
是否胎生:是 / 否
是否水生:是 / 否 / 有时
每个样本有一个类别标签,共分为 5 类:
哺乳类(5 个)
爬行类(3 个)
鱼类(3 个)
鸟类(2 个)
两栖类(1 个)
目标: 使用 CART 决策树,依据 基尼指数(Gini Index),在三个特征中选择最优的划分特征。
特征 1:体温(A_1 )
划分方式:
恒温(D_1 ):7 个样本(哺乳类 5,鸟类 2)
冷血(D_2 ):8 个样本(爬行类 3,鱼类 3,两栖类 2)
计算基尼指数:
对恒温样本:
对冷血样本:
加权平均基尼指数:
特征 2:胎生(A_2 )
划分方式:
胎生 = 是(D_1 ):8 个样本(哺乳类 5,鸟类 2,爬行类 1)
胎生 = 否(D_2 ):7 个样本(鱼类 3,爬行类 2,两栖类 1,哺乳类 1)
计算基尼指数:
胎生 = 是:
胎生 = 否:
加权平均基尼指数:
特征 3:水生(A_3 )
划分方式:
是(D_1 ):5 个样本(鱼类 3,哺乳类 1,鱼类/鸟类 1)
否(D_2 ):7 个样本(哺乳类 4,爬行类 2,鱼类 1)
有时(D_3 ):3 个样本(爬行类 1,鱼类 1,两栖类 1)
计算基尼指数:
水生 = 是:
水生 = 否:
水生 = 有时:
加权平均基尼指数:
结论:
基尼指数最小的特征是 "体温" ,因此在构建决策树时, "体温" 应作为当前最优的划分特征。
基于随机森林的决策分类
随机森林(Random Forest)是一种由多个决策树组成的集成分类器,由 Leo Breiman 和 Adele Cutler 提出。顾名思义,随机森林通过随机的方式构建一片 "森林" ,其中每棵树都是一个独立的决策树,彼此之间相互独立、没有关联。
算法原理
随机森林属于集成学习(Ensemble Learning)方法的一种,它的核心思想是将多个弱分类器(即决策树)集成,提升整体模型的稳定性和预测精度。
整个训练过程包括两个关键的 "随机" 过程:
随机采样数据(Bootstrap):对原始训练集进行有放回采样,生成若干子训练集,每棵树使用一个不同的子集进行训练。
随机选择特征:在每个树的节点划分时,从所有特征中随机选取一部分,再从中选择最优划分特征,而非使用全部特征。
每棵树独立训练,最终的预测结果通过多数投票(分类问题)或平均(回归问题)得到。
随机森林的特点与优势
优点
适用于分类与回归任务:随机森林能够同时胜任这两类问题,并在实际应用中都表现出色。
抗高维数据能力强:即使面对数千甚至上万个特征,也能良好运行。它还能评估每个特征的重要性,是一种有效的降维工具。
处理缺失值能力强:即使数据存在大量缺失,随机森林依然可以保持较高的预测精度。
应对类别不平衡问题:随机森林通过对样本和特征的随机性引入,有助于缓解不平衡数据带来的偏差。
无需独立测试集:
随机森林中的 Bootstrap 采样会自动留下一部分未被抽到的数据(约 1/3),称为 袋外样本(Out-of-Bag Samples)。
利用这些数据,可以直接估计模型的泛化误差(称为 OOB Error),无需额外划分验证集。
可扩展性与并行性好:每棵树可以独立训练,天然支持并行化,加快训练过程。
缺点
随机森林在处理回归问题时的表现往往不如在分类任务中那么理想,原因在于它无法生成连续的输出结果。当用于回归时,随机森林通常难以预测超出训练数据范围的数值,这在面对带有特殊噪声的数据时,可能会导致模型过拟合。
此外,对于统计建模的角度来说,随机森林更像是一个 "黑盒" ——我们难以真正了解模型内部的运行机制,只能通过调整参数或更换随机种子来尝试获得更好的结果。
随机森林的构造方法
随机森林的建立主要包括两个核心步骤:随机采样和完全分裂。
随机采样
在构建每棵树时,随机森林会对输入数据进行 "行" 和 "列" 的双重随机抽样,但两者的方式略有不同:
对于样本(行)的抽样,采用的是有放回的方式,即同一个样本有可能被重复抽中。假设原始样本有N 个,那么每棵树依然会抽取N 个样本用于训练,只不过其中可能包含重复项,也会有一部分原始样本未被选中。这种方法有助于提升模型的泛化能力,降低过拟合的风险。
对于特征(列)的抽样,则是无放回的方式。每次在所有M 个特征中,随机选择m 个(通常m \ll M )用于节点的分裂判断。这样可以使不同树之间具有更多差异性,提高整体模型的鲁棒性。
完全分裂
在构建决策树的过程中,每个节点都会尽可能分裂,直到无法继续分裂为止。这意味着:
一个节点要么是终结节点(叶节点),因为样本已经不能再划分;
要么是该节点中的所有样本都属于同一类别,无需再继续分裂。
这种不剪枝的做法使得每棵树都可以完整生长,从而最大限度地保留了数据中的信息。
具体构造流程如下:
设训练集中有N 个样本,M 个特征;
每棵树从原始样本中有放回地抽取N 个样本,构成当前树的训练集;
对于每个节点,从M 个特征中随机选择m 个特征,在这m 个中找到一个最佳分裂点进行划分;
重复分裂,直到树完全生长(无需剪枝);
用未被该树选中的样本(称为 "袋外数据" )来评估模型的预测误差;
最终,模型由多棵独立构建的树组成,每棵树都有自己的样本子集和特征子集。
随机森林的整体性能取决于两点:树之间的相关性 和 每棵树的分类能力。如果不同树之间的相关性较低,同时每棵树都有较好的判断力,那么整个森林的错误率就会更低。相反,如果树之间太相似,模型的泛化能力可能会下降。
随机森林实例
问题描述:
我们希望通过车厘子的 质量、鲜红度、直径、产地 以及 新鲜度 这五个特征,来预测它属于哪个价格层级。
我们假设车厘子落入三个层次是均匀分布,即先验概率
1. 构建随机森林模型
我们将随机森林中的每棵树看作是一棵CART决策树。由于车厘子有5个特征,因此这里我们构建了一个包含5棵CART树的随机森林。
下图展示了不同特征在每个价格层次中的出现概率,用于训练模型:
2. 写出某个特定车厘子价格层次下的条件概率
接下来,我们将一颗车厘子的相关信息输入模型进行预测
3.计算每个层次下的联合概率(未归一化)
模型会根据每棵树的判断输出对应的概率分布,这些后验概率通过以下公式计算:
也就是:
层次1:
层次2:
层次3:
4. 归一化概率
A = 0.00408
B = 0.000918
C = 0.0000021
归一化公式:
求和:
计算每个概率:
P(1 \mid x) = \frac{0.00408}{0.0050001} \approx 0.816
P(2 \mid x) = \frac{0.000918}{0.0050001} \approx 0.1836
P(3 \mid x) = \frac{0.0000021}{0.0050001} \approx 0.00042
5. 最终判断
在朴素贝叶斯下,根据模型的输出结果,这颗车厘子被预测为属于价格层次1。
决策树的剪枝
决策树模型容易发生过拟合,为了解决这个问题,可以采取以下几种方式:
设置终止条件,限制树的生长,防止分支过细;
在树构建完成后进行剪枝,简化模型;
使用基于 Bootstrap 的集成方法,如随机森林。
其中, "剪枝" 是避免决策树过拟合的重要手段。CART 决策树通常会先生成一棵 "完全生长" 的树,然后从底部剪去部分子树,使模型更简单、泛化能力更强。剪枝方法主要分为两类:预剪枝(Pre-Pruning) 和 后剪枝(Post-Pruning)。
预剪枝(Pre-Pruning)
预剪枝是在构建决策树的过程中就判断是否继续划分节点。若当前划分不满足某些条件,则提前停止,不再继续生长分支。
常用的停止条件包括:
限制树的最大深度;
限制叶节点的最大数量;
限制每个叶节点最少包含的样本数;
节点划分后带来的信息增益低于某一阈值;
使用验证集检查当前划分是否提升模型精度。
预剪枝的好处在于训练速度快,能有效降低过拟合风险。但缺点是可能会出现欠拟合,因为某些当前看来效果不佳的划分,后续可能会带来更好的表现。
后剪枝(Post-Pruning)
后剪枝是在生成整棵决策树之后,再从底向上逐步检查每个非叶子节点是否可以合并为一个叶子节点。
常用做法是:
利用验证集评估节点划分前后的预测精度;
如果节点划分后未带来精度提升,则将其对应的子树剪掉,并将该节点转为叶节点。
后剪枝的优势在于泛化能力更强,欠拟合风险小。但由于需要先构建完整树并逐一检查每个节点,因此训练时间较长。
后剪枝算法
为了提升决策树在未知数据上的泛化能力,避免过拟合,我们常使用后剪枝算法。这类方法通常先生成一棵完整的树,再对其结构进行简化。常见的后剪枝方法包括:
错误率降低剪枝(Reduced-Error Pruning, REP)
REP 是一种较为简单的后剪枝方法,它通过引入验证集来判断是否保留某个子树。
基本流程:
将可用数据划分为训练集和验证集,通常采用 2/3 用于训练,1/3 用于验证;
用训练集生成完整的决策树;
对每个非叶子节点进行如下处理:
删除该节点下的子树;
将该节点转化为叶子节点,并赋予其训练集中最常见的分类;
若修改后在验证集上的准确率没有下降,保留修改,否则还原;
自底向上重复执行以上过程,直到进一步剪枝会影响模型性能为止。
优缺点:
优点:直观简单,有助于减少过拟合;
缺点:依赖额外的验证集,在数据量较小的情况下不适用,且容易忽略训练数据中的特征,反而导致过拟合验证集。
悲观剪枝(Pessimistic Error Pruning, PEP)
PEP 是 C4.5 决策树中使用的剪枝策略。不同于 REP,PEP 不需要验证集,而是通过对训练误差的 "悲观估计" 来决定是否剪枝。
核心思想:
即便剪枝会增加训练误差,也可能在新数据上带来更好的表现。因此,PEP 引入了惩罚项,对每个叶子节点假设其预测会出错一定比例,通常加上常数0.5 ,以便更 "保守" 地估计模型的误差。
具体计算方式如下:
假设一个叶节点覆盖N 个样本,其中有E 个分类错误,则其误差估计为:
对于一棵拥有L 个叶子节点的子树,总体误差估计为:
由此可见,尽管一棵子树包含多个叶节点,在训练集上看似具有较小的误判率,但在引入惩罚因子后,情况可能会发生变化。由于我们对每个叶节点的误差估计中都加入了修正项(如+0.5 ),所以子树的整体误差不一定优于将其替换为一个叶节点的结果。
当我们考虑将一棵子树替换为一个单一的叶节点时,新的叶节点的误判个数记为J ,同样需要加入修正,变为J + 0.5 。虽然在未加惩罚时,子树往往在训练集上表现更好,但加上惩罚因子之后,如果子树的 "修正后误差" 显著高于被替代叶节点的 "修正后误差" ,就说明该子树可能存在过拟合,应当剪枝。
具体判断依据为:只有当剪枝后的误差显著低于原子树的误差(考虑误差的波动范围),才进行剪枝。判断公式为:
其中,误差的标准差由二项分布近似得出。
我们将一个子树的每次分类看作一次伯努利试验:分类正确记为 0,错误记为 1。假设该子树的误判率为e ,覆盖样本数为N ,那么子树的误判次数可以近似看作服从二项分布B(N, e) 。
因此,它的期望误判数和标准差可分别表示为:
在实际剪枝判断中,并不一定要误差超过一个标准差才剪枝。我们可以根据设定的置信区间和显著性水平,估算误差的上下限。然后,用误差下界作为规则性能的估计依据。
这种方法的效果是:当样本量足够大时,估计结果非常接近真实误差;而样本量小时,估计偏差增大,置信区间也更宽。尽管该方法在统计意义上并不严格最优,但在实际应用中表现良好。
PEP 算法采用自顶向下的剪枝策略,凡是符合上述剪枝条件的非叶节点都会被裁剪。然而,这种方式可能会先剪掉某个节点,导致其本应保留的子树一并被删,带来误判风险。
尽管如此,PEP 仍被认为是准确率较高的剪枝方法之一,在很多实际场景中都能取得不错的效果。
最小误差剪枝(Minimum Error Pruning,MEP)
在 MEP 中,我们希望通过先验概率和加性平滑来对某个节点的分类误差进行估计,从而决定是否进行剪枝。
1. 类别概率估计
对任意一个到达节点t 的样本,属于类别i 的估计概率为:
其中:
n_i(t) :节点t 上被判为类别i 的样本数;
P_{xi} :类别i 的先验概率;
N(t) :该节点包含的样本总数;
m :平滑参数(常用于控制先验的影响程度)。
2. 节点的期望误差估计
我们选取该节点中数量最多的类别c ,计算其分类正确的概率,然后反推出分类错误的期望值:
其中:
n_c :该节点中最多类别的样本数;
P_{xc} :该最多类别的先验概率。
这个E_s 就是如果我们把该节点直接当作叶子节点的情况下,预测错误的概率。
3. 子树分裂时的期望误差
如果不剪枝,保留当前节点的所有子节点,则该子树的总期望误差为:
也就是对每个子节点的误差进行样本数加权求和。
剪枝判断条件
若该节点作为叶节点的误差不高于保留分支的加权误差,即满足:
则剪去该子树,将当前节点变成叶子节点。
代价复杂剪枝——用于 CART 决策树
为了平衡模型的拟合效果与复杂度,CART 决策树采用代价复杂度剪枝策略来对已构建的决策树进行简化。
剪枝准则
CCP 使用以下目标函数来衡量一棵树的优劣:
其中:
W(T) 表示该树在训练集上的误差(或代价);
C(T) 表示树的复杂度,通常用叶子节点的数量表示;
\alpha 是控制误差与复杂度之间权衡的超参数,\alpha 越大越偏向剪小树。
核心步骤:
构建完整的决策树;
枚举所有可能的子树T_i (通过不同程度的剪枝获得);
计算每棵子树的W_\alpha(T_i) ;
选出W_\alpha 最小的子树,作为当前最优子树。
具体步骤
输入:CART 算法生成的完整决策树T_0
输出:剪枝后的最优子树T_a
算法步骤:
初始化:设k = 0 ,T = T_0
初始化最小权重系数:\alpha = +\infty
自下而上遍历所有内部节点t ,计算以下量:
C(T_t) :以t 为根节点的子树在训练集上的误差;
C(t) :将t 剪枝为叶节点后对应的误差;
|T_t| :子树T_t 的叶节点数;
利用公式计算每个节点的惩罚因子:
g(t) = \frac{C(t) - C(T_t)}{|T_t| - 1}更新当前最小惩罚值:\alpha = \min(\alpha, g(t))
再次自上而下遍历节点,若某节点满足g(t) = \alpha ,则将其子树剪掉,将该节点转为叶子节点(类别由多数表决决定),生成新树T
记录当前子树:设k = k + 1 ,\alpha_k = \alpha ,T_k = T
若当前树不是只有根节点的单节点树,则回到步骤 3,继续剪枝
最后,在生成的一系列子树\{T_0, T_1, ..., T_n\} 中,使用交叉验证选择预测效果最好的子树作为最优子树T_a
对比总结(四种剪枝法)
有研究表明,在决策树的整个生成过程中,剪枝阶段比建树阶段更为关键。即使使用不同的划分标准构建出的 "最大树" (Maximum Tree)有所不同,最终经过剪枝后,往往都能保留最重要的属性划分,从而得到更稳定、更具泛化能力的模型。