
图像分割
编辑理论部分
图像分割将图像划分成不同部分,其核心思想是将图像分解成同质的像素组,按照判别标准的不同可以实现不同的分割方法,分割可以是完整的也可以是不完整的,取决于具体情况。
分割在大方向上分为两类,语义分割和实例分割:
语义分割
实例分割
在医学图像处理中,语义分割可以标注出不同种类的细胞,实例分割可以详细识别同种细胞的个体
竞赛与训练集
图像分割是计算机视觉的重要课题,那肯定少不了很多竞赛,比如说,2021 年的“越野图像分割挑战”(Off-road Image Segmentation Challenge),需要在越野场景中分割道路、树木、岩石,这种分割就很特殊,一方面要处理复杂地形问题,还要考虑驾驶员视角、光照变化的情况。 也有很多大规模标注数据集,比如 COCO 数据集。
分割标准
图像分割的的核心在于选择哪种同质性标准来进行分割,同质性可以理解为共同的特点,我们找到哪些像素是一家的,哪些像素是另一家的,因此有以下几种同质性标准:
像素强度: 也就是亮度/灰度,比如简单的黑白图像可以通过亮度差来实现分割
颜色: 利用RGB值来进行分组,比如说包含不同水果的彩色图像,西瓜是红色的,那么和蓝莓就可以分开
纹理: 利用图像粗糙度或者重复图案来进行分组,比如毛衣、草地、墙砖
这只是最开始图像分割的方法,随着图像变得越来越复杂,这些方法只能作为图像分割算法的基石,现在需要高级算法来找到一副差不多图像中的不同区域特征的边界。
Horowitz 定义
Horowitz 在 1975 年提出了一种分割数学模型,用来描述分割的性质和目标。
一幅图像 I 可以被划分为 N 个不相交的子区域 S_i -->( S_1, S_2, \dots, S_N ),即:
注意,子区域是不相交的,也就是不重叠的,并且要覆盖完整个图像(好比拼图)
每个子区域 S_i 必须是连通的,也就是一个区域内,像素是相互连接的,不会有河流把同一区域内像素分开,不是东一块、西一块的,比如说一张猫的图片,猫的身体部分是一个区域,这个区域内,猫的头和脖子是不分家的,分开的那是路易十四
\forall i \in [1, N], \; S_i \text{ 是连通的} \Rightarrow P(S_i) = \text{True}相邻两个区域 S_i 和 S_j 如果属性不同,则不可以合并,也就是绝对没有交集。比如说猫的头和背景绝对不能合成一个区域,或者蓝色和红色绝对不能合并成一个区域。
\forall i, j \in [1, N], \; i \neq j \Rightarrow P(S_i \cup S_j) = \text{False}
在上面三个定义中, P 用来表示区域是否满足某种分割的标准,我们可以用方差标准:
\sigma_R 表示区域 R 的像素值的方差,如果方差 \sigma_R 小于某个阈值,那么这个区域 R 就是同质的。
我们同样可以用均值标准
代表了区域 R 中每个像素值 I(p) 与区域平均值 \mu_R 的差异,如果差值较小,那么说明区域像素集中且均匀。
分割算法需要满足下面三个条件:
唯一性: 同一张图像经过相同标准分割后应该产生一致的结果
稳定性: 对噪声具有鲁棒性,不会显著影响分割结果
可计算性: 计算代价不能太高,也就是算法要保证速度
图像分割的常见方法
基于阈值化分割: 最简单的方法,设置阈值把图像分割成不同的区域
基于区域生长分割: 从一个种子点或者多个种子点开始生成,逐渐扩展形成区域
基于边界检测分割 : 检测图像中的边缘(像素值变化剧烈),并以此来将图像划分成不同区域
基于深度学习分割: 例如 U-Net 和 Mask R-CNN,可以自动学习如何分割复杂场景。
基于阈值化/分类的分割方法
我们先看第一种最简单的方法,只通过简单的规则就可以把图像划分为前景和背景两类,即二分类。
二值化过程
对于一副灰度图像中的每个像素 I ,阈值化过程可以用下面的公式表示:
1 为前景,0为背景
阈值化分割的优缺点
优点
算法逻辑简单,计算量小,适合实时处理,特别是用于单一目标的快速分割。
适用于对比明显的图像,前景和背景的像素值差异大时,分割效果很好。
便于实现,只需设定一个阈值即可完成分割,无需复杂的模型或训练数据。
缺点
对阈值选择敏感,阈值设定不当会导致分割结果不理想。
不适用于复杂图像。
不适合多类别分割,多区域划分做不了。
阈值选择
不同的阈值会导致完全不同的分割结果,因此我们要想办法确定最佳阈值。因此选择阈值的方法主要包括:
监督式方法
观察直方图,手动选阈值。适用于简单图像,复杂图像的直方图分布不明显。
自动选择
利用算法(如 Otsu 方法或 K-means)自动计算最优阈值,适合批量处理图像。
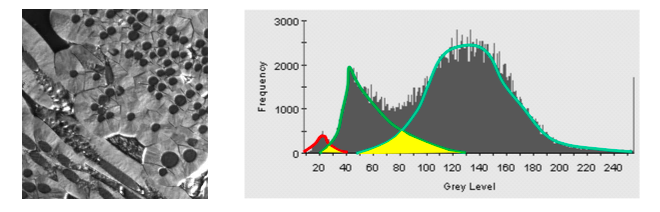
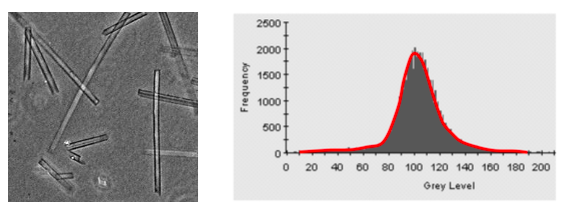
现在我们研究监督式方法中的直方图来找到阈值,其思想是我们把像素强度分布排开,如果直方图呈现双峰(前景、背景),那么这种情况直接中间一刀切开,阈值化方法就很适用。如果图像再复杂一点,两个峰之间有重叠,那么就麻烦了,我们对阈值的选择就有讲究了,一般来讲,低阈值可以保留细节,但是噪声多,中高阈值会导致细节丢失,但是能去噪。

有的时候图像直方图不仅仅是理想双峰形式,而是单峰形式(不可能分离),或者多峰形式,这个情况下我们要找到更灵活的分割方法,比如说 多阈值分割,比如说下一章节的区域生长法,比如说 K-means 聚类算法,或者基于深度学习求解
多阈值分割
下面我们先介绍多阈值分割方法,我们设置多个阈值,来将图像划分为不同区域,数学描述形式为:
s_b 和 s_h 是低阈值和高阈值。
满足条件 s_b \leq I \leq s_h 的像素被归为前景,其余像素被归为背景。
比如挑苹果,我们把100g到200g之间的苹果挑出来
Naïve 自动阈值化方法
也是老派分割方法,它核心是计算像素分组的平均灰度值,然后慢慢调整阈值,一直到结果稳定,下面我们介绍其流程
首先我们要计算他的直方图,统计每个灰度值的像素数量,得到灰度值分布情况,标准操作。
然后我们要设置初始阈值 T_0 ,随便设就行,可以选灰度值范围中点 T_0 = 127 。
再根据阈值 T_0 将像素进行分组,灰度值小于 T_0 的像素叫做 G_1 ,灰度值大于等于 T_0 的像素叫做 G_2 ,因此我们可以分别计算出 G_1 和 G_2 的平均灰度值:
最后使用平均灰度值来更新阈值 T :
不断循环迭代,重复上面步骤,直至收敛(阈值的变化小于一个预设的阈值 \varepsilon ):
这个算法有点天真,虽然是自适应算法,但是迭代来迭代去针对的还是直方图双峰分布,对复杂多峰直方图弄不了,很容易陷入局部最优解
Fisher 算法
还是针对直方图来找到最佳阈值,我们的目标是将像素划分为不同的类别,同时最小化类别内的灰度值波动(惯性),这样像素就尽可能不偏离所属类别中心。
首先我们需要先定义一个分区 P = \{C_1, C_2, ..., C_N\} ,也就是直方图被划分为 N 个类别( C_1, C_2, ..., C_N ),每个类别对应一定的灰度值范围。例如: C_1 = [0, t_1] , C_2 = [t_1 + 1, t_2] ,这里的 t_1, t_2, ..., t_{N-1} 就是不同类别之间的分割阈值,算法的目标就是找到这些最优分割阈值。
然后我们需要计算惯性 W(P) ,它表示像素灰度值偏离类别区域中心值的平方误差加权和:
h(k) 表示灰度值 k 的频率(直方图的高度)
G(C_i) 表示类别 C_i 的中心值,计算公式为:
G(C_i) = \frac{\sum_{k \in C_i} k \cdot h(k)}{\sum_{k \in C_i} h(k)}
最后我们调整分割点,然后找到能使 W(P) 最小化的最佳分区,从而实现最佳的灰度值分割。
Otsu 算法(Fisher加速版)
Fisher 算法的确能找到最佳的阈值,但是我们也看到了其数学公式计算的复杂度,因此Otsu 算法是它的加速版本(只适用于二值分割)。它的核心思想是最大化类间方差来加速算法,通俗一点就是衡量两划分区域之间的差异,两区域差别越大,那么分割效果就越好。
以上就是阈值分割方法,我们可以看到其优点是,算法简单,原理简单,找到阈值就可以了,而且计算复杂度相比而言比较低,适合快速处理。
K-means 聚类算法
下面我们看一种 新的算法,叫做 K-means 聚类算法,它是一种常用的无监督学习算法,可以将数据聚类(就是分组),它的核心目标是最小化数据点到所属簇中心的距离平方和,从而将数据划分为 K 个簇。一般我们用它来完成多维度特征的分割。
给出其算法流程:
首先进行初始化,随机选择 K 个点作为初始聚类中心(质心)
然后分配簇,计算每个数据点到 K 个质心的距离,将数据点分配到最近的质心所在的簇
然后更新质心,具体为对每个簇中的数据点求平均值,将该平均值作为新质心
其中 n_j 为簇 j 中的点数, x_i 表示簇中的点。
重复步骤 2 和 3,反复分配点和更新质心,直至质心位置不再发生显著变化(达到收敛)
这个算法的优点是原理简单,找质心 - 分配点 - 更新质心,适合快速处理。它的缺点是 a)我们需要一个初始 K 值,也就是预设簇数,很多情况下这个 K 未知。并且 b)算法对初始聚类中心 K 值很敏感,选的不好就导致局部最优解。c)同时 K-means 假设每个簇是球形且等方差的,如果是数据分布复杂,那就没得玩了。 d) 最怕遇到极端点,那么质心位置就直接被显著影响了,聚类效果直接被破坏。
与阈值方法相比,K-means 更加灵活,能处理高维特征。
连通组件标记
在图像分割中,二值化是最基础的步骤,用来粗略分离前景和背景,不能区分前景中不同对象,因此我们现在需要对前景的独立兑现进行标记,赋予唯一的标签,这一步叫做对象标记
接下来我们介绍连通组件标记算法,它用来识别二值图像中的独立区域,判断哪些像素是连通的,并将这些连通像素赋予相同的标签,从而区分不同的对象。
1966年,Rosenfeld提出了经典的两步法,用于标记二值化图像中的独立连通区域,实现简单,但由于需要两次扫描,计算效率相对较低。
(A) 第一次扫描:遍历二值图像,为每个前景像素分配临时标签,并建立等价关系(即相邻像素属于同一区域)。
首先进行初始化,把所有像素的初始标签标记为空,然后进行逐像素扫描图像,对每个前景像素检查其已经处理的邻域标签,我们把左上、上、右上、左侧四个邻域的像素,分别记为e_1, e_2, e_3, e_4。
然后根据邻域中非空标签的数量N,对当前像素赋予标签:
如果 N = 0(邻域无非空标签),那么当前像素是新区域的起点,分配给它一个新的标签
如果N = 1(邻域有一个非空标签),那么当前像素继承邻域中的唯一标签
如果 N > 1(邻域有多个非空标签),那么当前像素位于多个区域的交汇点,我们要选择其中一个标签作为当前像素的标签
我们需要记录这些标签之间的等价关系,如果发现多个标签需要合并的时候,那么将他们记录为等价标签对,即标签属于同一区域
(B) 第二次扫描: 根据等价关系把临时标签合并为最终标签
首先我们解析等价关系表格,把等价标签都映射为唯一的最小终极标签,然后我们给出最小终极标签更新公式:
T(e) 是标签e 在等价表中的当前映射值。
这样通过递归替换,将所有等价标签最终映射到同一最小标签,消除了冗余标签。最后我们再次遍历图像,更新每个像素点临时标签为等价表中的最小终极标签。
完成所有操作后,属于同一区域的像素会被赋予相同的最终标签。
2011年,Lacassagne 提出了针对传统连通组件标记算法的三步法优化,相较于两步法(初始标记和标签合并),三步法显著提高了效率,降低了计算复杂度:
首先初始标记,快速扫描图像,初始分配临时标签,记录像素可能属于的区域
优化合并策略,减少不必要的合并,防止增加计算量
将临时标签替换为最终标签,生成完整的标记后的图像
区域融合分割
我们之前都是划分图像,把大的化成小的,区域融合分割是把小的合体,不断合并相似的图像区域,把像素层次相似的内容融合成有意义的区域图像。最终图像被划分为若干互不重叠的区域。
因此为了实现这个过程,需要把每个像素都看成一个小小的区域,然后建立邻接图(RAG),它用来描述小小区域之间的连接关系,然后算法会合并相似度高的相邻区域,完成融合
邻接图(RAG)
每个节点代表一个区域(小到像素,大到区域),每个边表示两个区域之间的相邻关系,这个边是带权重的,用来表示两个区域的相似程度(举个例子,我们可以用颜色来表示两区域的相似度,颜色越近相似度越高)
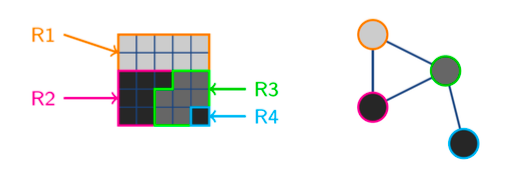
如图所示,有四个相邻区域, R1, R2, R3, R4 ,可以变成右边四个节点,颜色代表相似性
算法步骤
a) 首先我们进行初始化,图像被视作分为小单元,基于这些像素级别的单元,我们构建初始RAG邻接图,来此记录区域之间的相邻关系和相似性
b) 先找出所有的相邻区域对,然后计算相邻区域的相似性,把他们的相似性从高到低排列,储存为一个列表
c) 我们通过迭代寻找最佳的融合对: 在排序列表中找到两个最相似的相邻区域,判断他们是否满足融合条件,如果满足,最后将这两个选择后的区域合并为一个新区域,用一个新节点表示合并后的区域,删除旧节点的边,重新连接和其他区域的关系,重新计算与其他区域的相似性
d) 重复迭代进行区域融合,直到所有区域都不能再融合了(达到阈值、达到分割区域的数量)。
通俗来讲,区域融合分割就是拼图游戏,每个像素是初始拼图块,RAG图是拼图说明书,哪些拼图相邻、哪些图案类似,融合过程就是根据图案相似性把相邻拼图块拼到一起,构成一个大拼图单元最后把几个大区域合并到一起。
区域相似性与同质性
在区域融合分割中,判断区域是否可以合并的关键在于相似性和同质性。
我们用以下指标来判断合并后区域是否合理:
全局方差: 如果合并后的区域方差过大,说明区域内部差异过大,可能不该合并。 方差越小,表示区域内部的像素值更一致,也就是同质性更高。
偏离平均值的比例: 合并后的区域中像素值与平均值偏离一个标准差以上的像素所占比例,比例越低,说明区域内部的像素更趋近于平均值,表示区域更“均匀”或同质性更高。
当前我们可以在合并前进行初步分析,来大体推测一下能否判断它们的相似性:
归一化的差异分散度: 如果两个区域的像素值分布非常接近,说明可以合并
最小区域的大小: 小区域通常不稳定,优先考虑将两个小区域合并,形成一个更稳定的区域。
边界长度比例的倒数: 如果两个区域共享的边界较长,说明它们连接更紧密,适合合并。
将上述标准综合起来,可以定义一个混合相似性函数 f(R_i, R_j) ,用于量化两个区域的相似性:
f_{sim}(R_i, R_j) :表示区域间的内容相似性。
f_{size}(R_i, R_j) :考虑区域大小的标准。
f_{frontier}(R_i, R_j) :反映两个区域的边界关系。
自适应金字塔融合
传统区域融合是把相邻两个区域逐对合并,金字塔融合则一次性合并多个区域,按组合并,显著加速算法效率。
同时,它是分层来分割图像的,先从底层像素级开始合并,一直到顶层大区域合并。每次保留幸存节点,合并非幸存节点以减少冗余
算法步骤
a) 首先初始化,从像素开始,构建 8-邻接 邻接图,记录像素级别区域连接关系
b) 然后选择符合标准的幸存节点,幸存节点不允许相邻,避免冗余
c) 把非幸存节点合并到幸存节点中,这个合并到依据是之前的相似性函数 f(R_i, R_j) ,选择最相似的幸存区域。
d) 最后迭代根据合并后的新节点,重新建立关系,逐层合并,一直到顶层
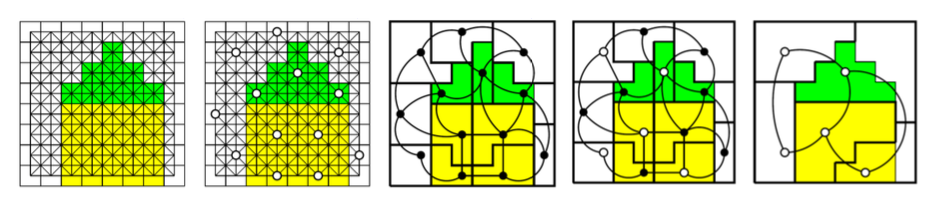
从上图可见,最左边图像被分割成大量的小块,作为最底层的分割单元,然后选中白色的幸存节点,代表当前层级中保留的代表性区域,然后非幸存节点和幸存节点合并变成黑色,这个时候初步区域划分已经形成,然后再次选中幸存节点,再次和非幸存节点合并生成了顶层区域。
Split & Merge 方法
Horowitz 和 Pavlidis 于 1976 年提出Split & Merge 方法,结合了区域划分和区域融合两种策略,两策略交替执行,能实现局部到全局的分割优化
原理
Split & Merge 方法分为两个阶段:基于划分的分割和基于融合的分割
首先我们先执行分割操作,我们将整个图像视为一个初始区域,然后用四叉树算法进行递归分割,变成小的子区域,然后和之前分割算法步骤相同,分割后检查同质性,满不满足继续划分的条件?最后到达阈值时候终止。
然后再执行融合操作,还是之前那一套,检查相似性,如果满足相似性标准就合并,然后用RAG拼接图表示区域连接关系,逐渐合并相邻同质区域,一直到达阈值。
算法流程
上面已经介绍差不多了,首先初始化,构建四叉树,其次Split 阶段,开始划分图像,然后Merge 阶段,开始合并区域,两阶段交替进行,不断优化分割结果。
优缺点
交替划分融合可以平衡过度分割或者欠分割的情况,比如说复杂区域可以不断分割来细化结果,均匀区域可以融合防止冗余

从上图可见,这个方法的缺点在于分块情况明显,纹理复杂的区域存在过多的小块
Graph-Cut 分割方法
我们利用图切割算法找到最佳的分割方案,来将图像分割成不同区域。
原理
图像被表示为一个无向图 G = (V, E) :
节点集 V :每个节点代表图像中的一个像素或区域。
边集 E :连接节点的边,表示像素之间的相似性关系。
切割
切割是从图中选取一组边,从而将图划分为两个子集 A 和 B 。切割是有代价的,其代价被定义为切割边的权重之和:
W(u, v) 是边 (u, v) 的权重,表示像素 u 和 v 的相似性。
W(A, B) 表示从 A 到 B 的所有被切割边的权重之和。
最优分割
让上面切割代价最小,就是最优分割
A) 最小切割: 需要找到一种切割来让切割代价最小,也就是我们要找到一组权重之和最小的边,将图像划分为两个部分
B) 归一化切割: 最小切割方法可能导致不平衡的分割,比如说孤立小区域,因此我们需要引入归一化因子,平衡切割代价与区域大小,更适合复杂情景
W(A, V) 和 W(B, V) 表示区域 A 和 B 与整个图的连接权重和。
分割流程
a) 首先将图像像素作为节点,基于相邻像素特征来定义边的权重
b) 利用最小切割或者归一化切割算法来找到最佳切割位置
c) 不断递归分割,对每个部分都应用Graph-Cut,细化分割区域
优缺点
很好的平衡内部区域的相似性和区域的差异性,适合分割复杂图像,避免过度分割问题
计算代价高,不适合处理大规模图像
区域生长
基于种子的分割方法,从一个初始点开始(种子),将与当前区域相邻且满足同质性条件的像素加入到区域中,逐步的生长出整个区域。方法简单直观,但是对初始种子选择和生长条件依赖大。
核心步骤
首先进行种子初始化,可以从一个初始点开始,也可以从一个区域开始,可以手动指定,也可以通过算法自动选择。
然后按照同质性的标准,找到与当前区域相似的像素,把它们加入到区域中,生长过程会一直重复到不再有像素可以加入其中。
如果我们同时有多个初始化种子,那么不同区域会并行增长,如果某个像素邻接多个区域的时候,会根据规则分配到最近的区域。这个时候可能存在多区域竞争问题,也就是不同区域的生长会竞争未分配的像素,这种竞争结果可能导致边界模糊。
生长停止的条件一般是达到某个相似性阈值,也就是区域内像素基本没差,区域间的像素差别很大,所有像素均已分配
算法流程
a) 在初始化操作中,我们先选择一个种子区域 R ,并将其边界像素加入一个 FIFO 队列 S (先进先出队列)。
b) 随后进行迭代生长操作:
从队列 S 中取出一个像素 p
判断像素 p 是否与当前区域 R 同质
如果 p 符合条件:
将 p 加入区域 R 。
将 p 的未被访问过的邻域像素加入队列 S 。
c) 终止条件: 当队列 S 为空时,停止生长,表示区域已经完全扩展。
阈值的影响
阈值决定了像素能否加入当前区域。如果阈值较小,只有非常像的像素才能加入,这样虽然会很精确,但是一方面增加计算量(过度分割),另一方面可能产生像素遗漏,丢失区域。如果阈值很大,那么可能把一些本不相关的区域也划分进来
优缺点
原理简单,容易实现,计算效率高,对于同质区域处理的很好,但是初始种子的选择很重要,阈值的选择很重要,对噪声也很敏感
分水岭算法
这个算法模拟一座山丘被水淹了的过程,按照像素梯度进行区域分割。我们把图像看成一个三位地形,亮的地方是山峰(梯度高的区域,例如边缘),暗的地方是山谷(梯度低的区域,例如区域中心),分水岭算法就可以把它们通过注水的方式分开。
算法流程
首先我们要找到图像的梯度值(橙色的部分),然后逐步注水,水从最低点不断填充低谷,然后随着水位上升不断扩大浸没区域,形成盆地,当不同盆地的水要相遇的时候,也就是分水岭线的时候,这个地方就是边界,因此分水岭线把地形分割成多个独立的区域,这就是最终分割。非常适用于处理图像中的目标分离或者边缘检测。
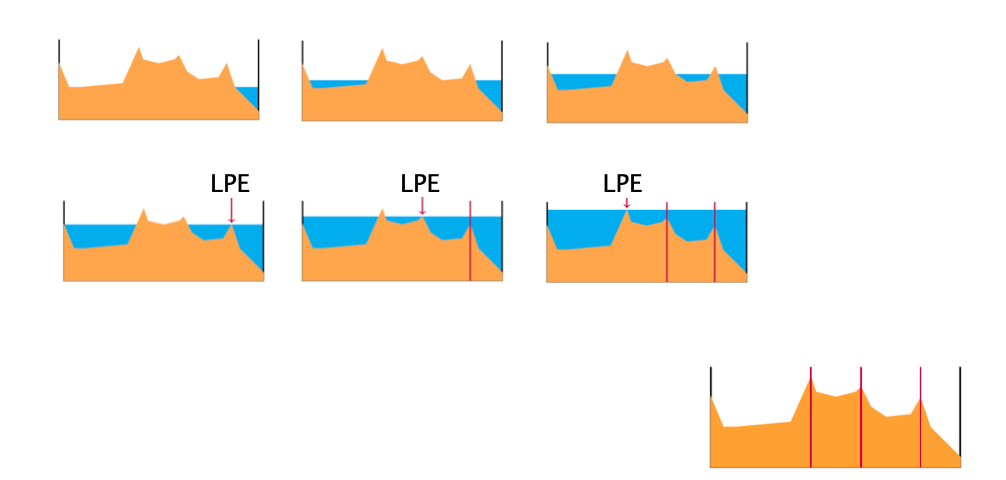
基于浸没线的分水岭算法(LPE算法) 宇宙无敌复杂
a) 首先我们要通过输入图像的梯度计算梯度范数图像 G ,梯度范数指的是图像中像素变化的强度,后续分割的时候要用。
b) 然后我们利用 G 的局部最小值(梯度极小值)来生成二值图像 B ,这些局部最小值是图像中潜在的分割边界。
c) 将二值图像 B 中的 1(局部最小值)赋予唯一标签,标签组成标签图 E ,这个标签图 E 代表着分割区域,其中每个像素存储着一个区域标签或者未分配标签。
d) 然后按梯度值从低到高顺序遍历图像像素来更新标签,逐步扩展区域确保从低梯度向高梯度区域生长
选择图像 G 中梯度值为 g 的像素点 s (尚未被标记的)
构造向量 E_s ,记录 s 邻域中 E 的所有标签
根据邻域标签为像素点 s 分配新标签:
如果 E_s 中存在区域标签或“LPE”标签,分配这些已有标签(代表 s 属于已有区域)
如果 E_s 中没有标签,那么就分配一个新标签 M
将所有标记为 S 的像素点添加到列表 L (FIFO顺序队列)
e) 遍历列表 L ,每次都从 L 中提取一个像素点 s ,查看这个 s 邻域的所有标签:
如果邻域只有一个区域标签或者LPE标签,则将该标签分配给 s
如果邻域中有多个标签冲突,则将 s 标记为 LPE(分水岭线)。
将 s 的未被访问的邻域像素添加到 L 中。
f) 新盆地生成:找到所有标记为 M 的像素点(未明确归属区域的点),使用这些点生成新的二值图像 B ,作为下一步新盆地的起点。
g) 更新标签图 E : 对新的二值图像 B 赋予新的区域标签,更新后的标签图 E_M 表示新增的分割区域。
h) 将 E_M 中的新标签合并到标签图 E 中,确保标签值唯一性(避免冲突),通常通过偏移当前最大标签值来调整。
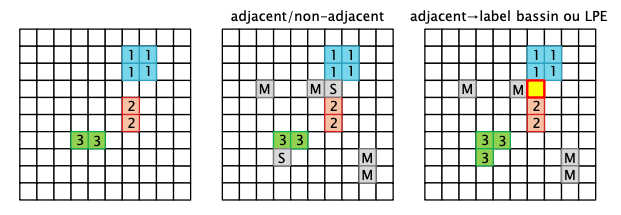
数字 1 2 3 代表已经标记的区域,代表不同的盆地
M 表示未确定的像素,比如说新的区域种子,或者是分水岭线
S:表示某个区域的边界点。
黄色高亮框:表示当前正在处理的像素点。
所以我们可以看到,最开始的初始种子区域被赋予唯一标签 1 2 3 ,然后种子向外扩展,邻域中的像素被加入到相邻的区域,如果一个像素状态不确定,那么就先暂时标记为 M ,如果遇到 S 这个情况,那么就说明遇到了分水岭线
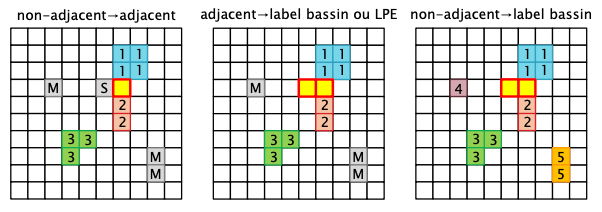
接下来我们将不确定的像素 M 分配区域,如果 M 周围只有一个标签,那么标记为区域,并根据邻域情况判断他是新标签还是已知标签,如果有多个标签并且无法归类,那么就是 LPE。
局限性:
图像中梯度的局部极小值过多时,会导致LPE算法产生过多的分割区域(过分割)。
改进方法:
在梯度计算之前,对图像进行平滑处理(例如高斯模糊)以减少梯度的局部极小值数量。减少分割的初始区域数量,从而降低过分割现象。
替换梯度极小值盆地为先验区域: 不再依赖梯度局部最小值作为算法初始化了,而是我们给他提供一些标记点,比如说先手动把蓝天白云标出来
上面我们介绍了基于梯度的局部极小值与标签传播的分割 LPE 方法,适用于图像梯度显著的场景,现在我们介绍一种可以适用于统计分析的场景(如纹理区域分割)的方法——马尔可夫分割,它更关注随机性和局部依赖性
马尔可夫分割
马尔可夫分割是一种基于马尔可夫随机场(Markov Random Field, MRF)的图像分割方法,它将图像分割建模为一种概率优化问题,利用像素间的局部依赖性来推断分割结果。
观察图像 A 的建模
图像被视为多个高斯随机过程的拼接结果,也就是说,每个区域都是由一个随机过程生成的,每个像素点强度值具有特定的统计特性(例如均值和标准差)。因此我们的目的就是根据像素的强度分布,把像素划分到不同的区域。
分割结果 \Lambda 的建模
分割结果被建模为一个隐藏的马尔可夫场随机过程,图像中的每个像素的标签都是一个随机变量,标签分布会服从马尔可夫场的性质: 像素标签的概率仅仅由它邻域像素的标签来决定,专业一点叫做,条件概率仅仅依赖于邻域信息。
符号定义
S (像素集合): S = \{s_1, s_2, \dots, s_N\} ,图像中的像素集合,包含 N 个像素点
A (强度图像): A = \{a_s \,|\, s \in S\} ,每个像素点 s 的强度值构成强度图像 A 。
\Lambda (标签图像): \Lambda = \{\lambda_s \,|\, s \in S\} ,每个像素 s 的分割标签 \lambda_s 构成标签图像 \Lambda 。
应用场景
马尔可夫分割适用于具有明确统计特性的图像场景,特别是涉及纹理、模式或统计特性区域的分割任务。
一阶统计量:均值(表示每个区域内像素值的平均强度)
二阶统计量:标准差(表示区域内像素强度的变化幅度)
马尔可夫分割数学建模
后验概率的分解
我们要找到能让后验概率 P(\Lambda | A) 最大化的那个分割标签图像 \Lambda ,因此根据贝叶斯公式,后验概率分布 P(\Lambda | A) 被分解为两个项:
P(A | \Lambda) :条件似然项,描述给定标签图像 \Lambda 时,观测图像 A 的生成概率。
P(\Lambda) :先验概率项,描述标签图像 \Lambda 的空间一致性。
条件似然项 P(A | \Lambda)
条件似然项假设像素强度值相互独立,可以分解为:
对每个像素点 s ,强度值 a_s 依赖于其所属的标签 \lambda_s 。
高斯分布建模
假设每个标签 \lambda_s 对应一个高斯分布,像素强度 a_s 的条件概率为:
\mu_{\lambda_s} :标签 \lambda_s 的强度均值。
\sigma_{\lambda_s} :标签 \lambda_s 的强度标准差。
条件似然项 P(A | \Lambda) 建模了像素强度分布,适用于纹理区域或强度有统计特性的场景。这正是之前提到的基于一阶和二阶统计量分割图像的基础。
先验概率项 P(\Lambda)
先验概率项 P(\Lambda) 被建模为一个马尔可夫随机场,描述标签图 \Lambda 的空间一致性:
\nu(s) :像素点 s 的邻域。
这表明每个像素点的标签 \lambda_s 仅依赖于其邻域 \nu(s) 的标签状态。
与吉布斯场的等价性
根据马尔可夫场和吉布斯场的等价性,先验概率 P(\Lambda) 可以表示为:
U(\Lambda) :系统的能量函数,表示标签图 \Lambda 的能量代价。
能量越低, P(\Lambda) 越大,对应更可能的标签分布。
能量函数的定义
能量函数 U(\Lambda) 表示为所有“团”(cliques,即互为邻域的像素集合)的代价总和:
W_c(\Lambda_c) :团 c 中标签的代价函数。
C :图像中所有的团集合。
团代价函数 W_c 的定义
一个简单的形式是自逻辑势函数(potentiel autologistique):
\beta :正则化参数,控制分割的平滑程度。
\beta > 0 倾向于邻域标签一致(平滑分割)。
\beta < 0 倾向于邻域标签不一致(更复杂分割)。
目标函数形式:
综上所述,马尔可夫分割问题等价于最小化一个能量函数 E(A, \Lambda) ,即找到最优的标签图 \Lambda :
P(A | \Lambda) :条件似然项,表示观测图像 A 在给定分割标签 \Lambda 下的概率。
P(\Lambda) :先验概率项,表示标签 \Lambda 的空间一致性。
通过对概率取负对数,将分割问题从概率最大化转化为能量最小化。
能量函数的分解
能量函数 E(A, \Lambda) 包括两部分:条件似然项和先验项:
第一部分(条件似然项):
\sum_{s \in S} \left( \log(\sigma_{\lambda_s} \sqrt{2\pi}) + \frac{(a_s - \mu_{\lambda_s})^2}{2\sigma_{\lambda_s}^2} \right)对每个像素点 s 计算高斯分布的代价,基于标签 \lambda_s 的统计特性(均值 \mu_{\lambda_s} 和标准差 \sigma_{\lambda_s} )。
这一项与观测图像 A 的强度分布相关,表示像素值 a_s 偏离其标签区域特性的程度。
第二部分(先验项):
\sum_{c \in C} W_c(\Lambda_c)通过所有“团”(cliques)的代价函数 W_c(\Lambda_c) ,描述标签 \Lambda 的邻域一致性。
这一项与马尔可夫场建模的先验概率 P(\Lambda) 对应。
局部能量 e_s 表示单个像素 s 的能量贡献:
第一部分(高斯代价):像素 s 的强度值 a_s 偏离其标签 \lambda_s 的统计特性的程度。
第二部分(邻域代价):像素 s 与其邻域标签一致或不一致的代价。
全局能量 E(A, \Lambda) 是所有像素点局部能量 e_s 的累加:
ICM 和 Metropolis 优化算法
在上述马尔可夫分割中,图像分割问题被建模为最小化能量函数 E(A, \Lambda) 的优化问题,目标是找到一个标签分配 \Lambda ,使得能量函数最小化。
因此介绍两种常用优化算法:ICM(迭代条件模式)和Metropolis 方法,来解决马尔可夫分割能力最小化问题。
iterated conditional mode (ICM)
ICM 是一种确定性贪心算法,通过逐步优化每个像素的标签来最小化局部能量。它的特点是简单高效,但容易陷入局部最优,并且容易被噪声干扰,难以得到全局最优的分割结果。
a) 首先进行初始化,从一个质量较高的初始分割标签开始,质量较高意味着初始标签要尽量接近全局最优,初始标签越好,那么就更容易找到全局最优的结果
b) 然后我们进行迭代优化,在收敛条件没有满足的时候,依次遍历每个像素点 s ,并执行以下步骤:
首先遍历像素点中的每个可能的标签,然后计算局部能量 e_s(\lambda_s) ,包括数据项和先验项
数据项:衡量像素强度 a_s 与标签 \lambda_s 的匹配程度。
先验项:衡量标签 \lambda_s 与邻域标签的一致性。
然后为 s 分配使 e_s(\lambda_s) 最小的新标签 \lambda_s
c) 这样不断循环迭代,一直到整体能量 E(A, \Lambda) 收敛到一个局部最小值
这个算法的优点是,是确定性算法,保证收敛,缺点是初始标签一定要选好,不然容易局部最优,算法就废了。
Metropolis 方法
Metropolis 是一种随机优化算法,通过引入随机性和接受“坏解”的机制来避免陷入局部最优。它适合优化复杂的能量函数,尤其是在分割问题具有多个局部最优时。
首先我们先进行初始化,生成初始标签分配 \Lambda ,并且设置温度参数 T ,温度参数 T 控制接受“坏解”的概率。温度设置的越高,算法越容易接受坏解;温度设置的越低,算法更倾向于优化当前解。
然后进入迭代过程,依次遍历每个像素点 s ,并且执行以下步骤:
先随机生成一个候选标签 x ,然后计算候选标签 x 对应的局部能量 e_s(x) ,计算当前标签 \lambda_s 的局部能量 e_s(\lambda_s) ,计算能量变化 \Delta e = e_s(x) - e_s(\lambda_s)
根据条件决定是否接受新标签 x :
如果 e_s(x) < e_s(\lambda_s) ,直接接受 x 。
如果 e_s(x) \geq e_s(\lambda_s) ,以概率 e^{-\Delta e / T} 接受 x ,其中 \Delta e = e_s(x) - e_s(\lambda_s) 。
这个算法的优点是,由于它是随机算法,可以接受局部劣化(坏解)状态,可以跳出局部最优。相比 ICM,metropolis 的随机性使得它适合复杂的能量函数优化,尤其是在存在多个局部最优的情况下能找到更优解。但代价是执行时间较长,效率低于 ICM。
模拟退火算法
模拟退火(Simulated Annealing)是对 Metropolis 算法的改进和扩展,是一种全局优化算法,基于物理学中的退火过程。通过引入温度参数 T ,算法在初期允许较大的随机跳跃,逐步探索全局解,随着温度逐步降低,随机性减小,算法逐渐收敛到一个局部解,最终可能接近全局最优。
原理
模仿金属退火的过程: 金属在高温下具有较大的粒子运动自由度,能够探索多种状态。随着温度逐渐降低,粒子运动受限,最终趋于稳定状态。
算法流程
a) 首先初始化,生成初始标签分配 \Lambda ,作为初始分割方案。设定一个较高的初始温度,用于大随机跳跃探索全局解
b) 然后进入优化收敛过程,针对每个像素点 s 进行以下步骤:
随机选择一个候选标签 x ,候选解表示像素 s 被赋予新标签 x 。
算新标签 x 的局部能量 e_s(x) ,以及当前标签 \lambda_s 的能量 e_s(\lambda_s) 。
条件接受标签 x :
如果 e_s(x) < e_s(\lambda_s) ,直接接受标签 x 。
如果 e_s(x) \geq e_s(\lambda_s) ,以概率 e^{-\Delta e / T} 接受候选解 x ,其中 \Delta e = e_s(x) - e_s(\lambda_s) 。
按照规则 T \leftarrow kT 逐步降低温度 T ,其中 k \in [0.8, 0.999] 是递减因子,用于控制温度下降的速度。
优缺点
继承了 Metropolis 算法的随机性。在高温阶段允许接受劣解,能够避免陷入局部最优解。控制温度逐步下降,可以减少随机性,最终收敛到一个稳定解,可能接近全局最优。更适合复杂能量函数优化问题,例如之前的 E(A, \Lambda) 。
初始温度 T 和递减因子 k 的选择直接影响算法性能,并且算法计算复杂度高
算法比较
Superpixels 方法
Ren和Malik在2003年提出Superpixels方法,通过聚合相邻像素,将其分组为更大的“超级像素单元”,代替逐像素处理。
核心思想
把图像中的相似像素(如颜色相似、纹理一致)聚合成一个个区域,称为“Superpixels”,每个 Superpixel 是一组相邻的像素,具有相似的视觉属性。因此分组是基于图像的内容特征,而不是简单的网格划分,更加接近真实图像的分割结果。
同时相比逐像素处理,大大提高了计算效率。
Superpixels算法种类
Watershed 方法:基于分水岭算法(如 Compact Watershed)。
聚类方法:如 SLIC(Simple Linear Iterative Clustering),基于颜色和空间位置聚类,是最流行的方法之一。
图论方法:如 Random Walks,利用图的连接关系生成 Superpixels。
路径方法:如 Path Finder,通过像素的路径相似性生成 Superpixels。
密度方法:如 Mean Shift,利用像素的密度分布生成 Superpixels。
轮廓进化方法:如 Turbo Pixels,模拟轮廓进化过程生成 Superpixels。
算法特性
Superpixels 的数量直接决定了分割的精细程度。
紧致的 Superpixels 边界更平滑,而非紧致的 Superpixels 更能贴合图像内容。
SLIC(Simple Linear Iterative Clustering)
SLIC 是一种基于 k -means 聚类思想的 Superpixels 分割算法,通过混合颜色和空间距离,生成紧凑、均匀的 Superpixels,既保留图像的局部特性,又显著减少处理单元数量。
几何特性
固定数量的 Superpixels:SLIC 根据规则网格初始化聚类中心,控制 Superpixels 的数量和大小,生成平均尺寸一致的区域。
混合距离度量:SLIC 使用混合距离 D ,综合衡量颜色相似性和空间位置紧致性。
颜色距离 d_{lab} :反映 Superpixels 对图像内容的依附性。
空间距离 d_{xy} :控制 Superpixels 的形状紧致性。
d_{xy} = \sqrt{(x_k - x_i)^2 + (y_k - y_i)^2}参数 m :控制颜色和空间距离的权重。
m 大:更规则的形状,内容细节可能忽略。
m 小:更贴合图像内容,但形状可能不规则。
参数 S :控制 Superpixels 的平均大小,影响分割细腻程度。
复杂度控制: SLIC限制搜索范围为每个中心的 2S \times 2S 邻域,时间复杂度与像素数量线性相关,效率较高。
算法流程
首先进行初始化,在规则网格上初始化聚类中心 C_k ,表示颜色和空间位置 [l_k, a_k, b_k, x_k, y_k] 。将初始聚类中心移动到局部梯度最小的位置,以提高结果的稳定性。
然后进入分配阶段,在每个中心的 2S \times 2S 窗口内,计算像素到聚类中心的混合距离 D 。然后将像素分配给最近的聚类中心。
最后是更新阶段,我们重新计算每个聚类的中心点为当前聚类中所有像素的平均值。不断迭代,重复分配和更新阶段,一直到 E 收敛或达到最大迭代次数:
可以进行额外的边界后处理,合并小区域,保证分割的连贯性
优缺点
效率高,复杂度低,适用于大规模图像处理,可以通过 m 和 S 调节分割细腻程度与区域规则性。
Mumford-Shah 模型
核心思想
Mumford-Shah 模型通过最小化一个全局能量函数,将图像分割成多个均匀区域,兼顾区域的内容一致性和边界的规则性,生成全局优化的分割结果。
全局能量函数形式
Mumford-Shah 模型的全局能量函数为:
E_i(R_i) :内部能量,描述分割区域内的均匀性;
E_C(R_i) :复杂性能量,描述分割边界的长度或其他复杂性。
\lambda :权重参数,控制两个能量项的相对权衡性。
\lambda 小:复杂性限制较弱,分割边界更多,细节更加丰富;
\lambda 大:复杂性限制较强,边界更简单,分割更规则。
(A) 区域内部能量 E_i(R_i)
表示区域 R_i 内像素值的一致性,基于统计特性定义:
V 为区域的协方差矩阵, NT_r 为核迹运算符,描述区域内部的统计特性。
(B) 复杂性能量 E_C(R_i)
描述区域边界的长度或复杂性,鼓励分割结果更加规则。
边界过多会增加复杂性能量,从而被模型惩罚。
可变形模型(Deformable Model)
可变形模型是一种基于轮廓演化的图像分割方法,目标是通过迭代优化,使初始轮廓逐步贴合图像目标的边界。其经典方法是活动轮廓模型(Active Contour Model),又称“蛇”(Snakes)。
Kass等人在1987年提出了活动轮廓模型, 它通过能量最小化和迭代更新,实现轮廓的自适应演化。其初始条件和能量函数的设计关键,是图像分割中的重要方法之一。
能量函数
活动轮廓模型的能量函数表示为:
内部能量(平滑性约束): 控制着曲线的几何性质,保证曲线平滑且连续
\alpha : 控制曲线长度,抑制曲线过长。
\beta : 控制曲线弯曲程度,避免曲线不连续。
外部能量(图像驱动): 依赖图像梯度 \nabla I ,驱动曲线靠近强边缘区域。
\lambda : 平衡内部能量和外部能量的权重。
离散化与迭代过程
首先离散化初始轮廓,首先它被离散为 N 个点,形成向量表示:
其中 X_0 和 Y_0 分别表示曲线各点的横纵坐标。
然后进行迭代优化,每次迭代中,都会更新新的曲线点位置:
A : 包含 \alpha 和 \beta 的矩阵,描述内部能量的约束。
\gamma : 时间步长,控制轮廓移动的速度。
f_X, f_Y : 由图像梯度计算的外部能量。
迭代更新直到曲线收敛到能量最小值,贴合目标边界。
优缺点
能够生成平滑的分割边界,避免噪声干扰,在连续边界的目标分割中效果良好。
依赖初始轮廓位置,若初始轮廓偏离目标,可能无法收敛到正确边界。容易陷入局部最优,尤其是在复杂图像中。
算法实现
下面我们给出每个重要算法的完整代码和结果,重点在于更好的理解算法流程以及程序的实现。有些算法比如 fusion 或者 LPE 由于没能实现所以只给出必要的流程,没有结果图。
K-means 聚类分析结果
K-means 聚类算法很简单,核心思想就是把当前像素点和所有质心算距离,然后把像素点给离它最近的那个聚类。在下面的代码中,我们比较了三种不同版本的 K-means 算法,第一个版本 v1 就是基础理论教学版本,没有特别之处,v2 则用矩阵算距离,v3则请外援,直接调用人家已经写好的KMeans函数来做。下面给出代码的介绍
首先上来肯定规定一些有的没的库函数,比如说 numpy 是必须的,后面要比较三种算法速度所以 time 是必须的,然后要导入图像所以 matplotlib.image 是必须的,外部自定义函数 seg_tools也需要, v3方法要用到KMeans肯定也要导入进来,因此有;
import numpy as np
import time
import matplotlib.pyplot as plt
import matplotlib.image as mping
import seg_tools
from sklearn.cluster import KMeans下面我们就要开始函数定义了,就定义3个Kmeans函数就够了,我们先给出第一个 kmeans_v1
def kmeans_v1(data,centers): # 算法版本1
dim_v = np.size(data) # 提取数据维度,用于循环遍历所有像素
dim_c = np.size(centers) # 提取聚类中心个数,注意是个数,而不是值
label = np.zeros((dim_v,1),dtype = int) # 创建标签表格,其维度是数据点总数✖️1,后续每个像素点的标签都会存在这里面。
i = 0 # 迭代次数
flag = 1 # 只要还是1 那就抑制循环下去,最后达到结束条件将其置为0
while flag:
i = i+1 # 每次迭代加1
for j in range(0,dim_v): # 遍历像素点
for k in range (0,dim_c): # 遍历每个质心
d = abs(data[j] - centers[k]) # 计算当前像素点和每个质心的距离,目的是找到和哪个质心距离最短,那就把它归到那个类
if k == 0 or d < d_min: # 如果是第一个质心,那么肯定要把第一个质心的结果保留下来,相当于初始化。
# 如果后续质心的距离小于之前的距离,那么把新距离也保存下来,相当于更新距离。
d_min = d # 当前距离更新为最小距离
k_min = k # 当前质心索引找出来,后面记录到表中,代表这个像素应该归到这个类中
label[j] = k_min # 把索引记录到表中,好比表中记下了你是属于哪个班级的
# 更新每个质心的位置
for k in range(0,dim_c): # 遍历每个质心
centers[k] = np.mean(data[label == k]) # 找到所有类别为当前质心的像素点,对它们取平均值,然后得到新的质心值
if i > 1 and np.sum(np.abs(label - label_mem)) == 0: # 如果不是第一次迭代并且 标签表格没有变化 那么满足停止条件
flag = 0 # 停止
label_mem = np.copy(label) # 把当前得到的标签表格保存一份,留着下次对比 看看有没有更新
return label,i # 返回的是标签表格和总攻迭代次数如果看注释还没看明白的话,那么我再讲两句,其实思路很简单,首先要遍历像素,每个像素都要遍历质心(质心要自己选),遍历质心有什么用呢?为了计算它和质心的像素差,如果差的远,说明他和这个类的质心八竿子打不着,如果很近那我们默认这个像素应该归到这个质心所在的类中,这就是计算距离的目的。计算完距离后(和每个质心都要算距离,并且找到最小距离),找到对应类的索引,把索引存到标签表格中。
我们可以把标签表格看作一个花名册,现在就要统计每个学生(像素)是哪个班(类)的,我们采用的方法是,拿出一个学生看看它和每个班级的匹配度(距离),找到离得最近的那个班,然后把班名(类的索引)记到花名册(标签表格)上
然后花名册记好了,下面我们要更新质心的位置,为什么要更新?因为有新同学(像素)加进来了,他会影响整个班级(类别)的平均风气(区域像素平均值),间接影响下一次别的同学划分班级,所以我们要更新聚类中心。更新方法也很简单,我们有花名册(标签表格),找到花名册上所有是这个班级的学生(label == k),找到这些学生的像素值(data(label)),把像素值做mean平均即可。
最后我们设定停止条件,如果花名册不再变化了,也就是所有像素都处理了一遍,也就是没有新同学改变标签表格了的时候,就认为花名册已经被很好的填完了,迭代结束。
v2 v3大差不差,不再赘述。下面给出完整代码
import numpy as np
import time
import matplotlib.pyplot as plt
import matplotlib.image as mping
import seg_tools
from sklearn.cluster import KMeans
def kmeans_v1(data,centers): # 算法版本1
dim_v = np.size(data) # 提取数据维度,用于循环遍历所有像素
dim_c = np.size(centers) # 提取聚类中心个数,注意是个数,而不是值
label = np.zeros((dim_v,1),dtype = int) # 创建标签表格,其维度是数据点总数✖️1,后续每个像素点的标签都会存在这里面。
i = 0 # 迭代次数
flag = 1 # 只要还是1 那就抑制循环下去,最后达到结束条件将其置为0
while flag:
i = i+1 # 每次迭代加1
for j in range(0,dim_v): # 遍历像素点
for k in range (0,dim_c): # 遍历每个质心
d = abs(data[j] - centers[k]) # 计算当前像素点和每个质心的距离,目的是找到和哪个质心距离最短,那就把它归到那个类
if k == 0 or d < d_min: # 如果是第一个质心,那么肯定要把第一个质心的结果保留下来,相当于初始化。
# 如果后续质心的距离小于之前的距离,那么把新距离也保存下来,相当于更新距离。
d_min = d # 当前距离更新为最小距离
k_min = k # 当前质心索引找出来,后面记录到表中,代表这个像素应该归到这个类中
label[j] = k_min # 把索引记录到表中,好比表中记下了你是属于哪个班级的
# 更新每个质心的位置
for k in range(0,dim_c): # 遍历每个质心
centers[k] = np.mean(data[label == k]) # 找到所有类别为当前质心的像素点,对它们取平均值,然后得到新的质心值
if i > 1 and np.sum(np.abs(label - label_mem)) == 0: # 如果不是第一次迭代并且 标签表格没有变化 那么满足停止条件
flag = 0 # 停止
label_mem = np.copy(label) # 把当前得到的标签表格保存一份,留着下次对比 看看有没有更新
return label,i # 返回的是标签表格和总攻迭代次数
def kmeans_v2(data,centers): # 第二种版本
dim_v = np.size(data)
dim_c = np.size(centers)
ci = np.reshape(centers,(1,dim_c)) # 把 质心 尺寸重塑成二维
i =0
flag = 1
while flag:
i = i+1
d = np.abs(data * np.ones((1,dim_c)) - np.ones((dim_v,1)) * ci ) # 计算距离的时候是矩阵计算
label = np.argmin(d, axis=1)
for k in range(0,dim_c):
ci[0,k] = np.mean(data[label == k])
if i > 1 and np.sum(np.abs(label- label_mem)) == 0:
flag = 0
label_mem = np.copy(label)
return label, i
def kmeans_v3(data, centers): # 第三种版本
data_set = np.dstack(data.flatten())
model = KMeans(n_clusters=centers, n_init=10) # 使用库中已经写好的算法
model.fit(data_set[0].T)
return model.labels_
seg_tools.init() # 外部自定义函数,要先初始化
I =mping.imread('implant.bmp') # 读图
dim_y,dim_x = np.shape(I) # 提取图片尺寸
data = np.reshape(I.astype(float),(dim_y*dim_x,1)) # 不可能把一整张图片扔到算法里去算,因此要把一张图片展开成一列像素,所以这个操作把图片转为1维列向量
centers = np.array([50,150,200]) # 初始质心,随便设的
t1 = time.perf_counter() # 计算时间用的,不必要
for n in range(0,100): # 还是算时间用的,算一次算法运行时间不准,所以取个100次,得到平均时间
label1,i = kmeans_v1(data,centers)
t2 = time.perf_counter() # 算时间用的,不必要
print('V1 iteration:', i )
print('V2 temps:', (t2-t1)/100)
# 使用 kmeans_v2
t1 = time.perf_counter()
for n in range(0, 1000):
label2, i = kmeans_v2(data, centers)
t2 = time.perf_counter()
print('V2 iterations:', i)
print('V2 temps:', (t2 - t1) / 1000)
# 使用 kmeans_v3
t1 = time.perf_counter()
for n in range(0, 10):
label3 = kmeans_v3(data, 3)
t2 = time.perf_counter()
print('V3 temps:', (t2 - t1) / 10)
# 绘制结果
seg_tools.draw_uint8(I)
seg_tools.draw_labels(np.reshape(label1, (dim_y, dim_x)))
seg_tools.draw_labels(np.reshape(label2, (dim_y, dim_x)))
seg_tools.draw_labels(np.reshape(label3, (dim_y, dim_x)))
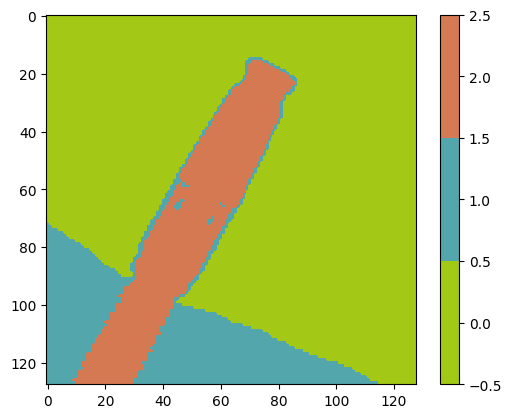
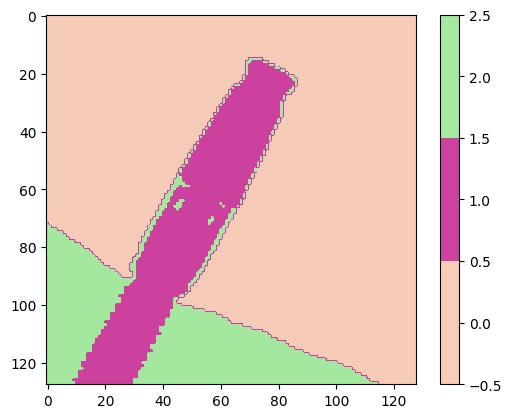
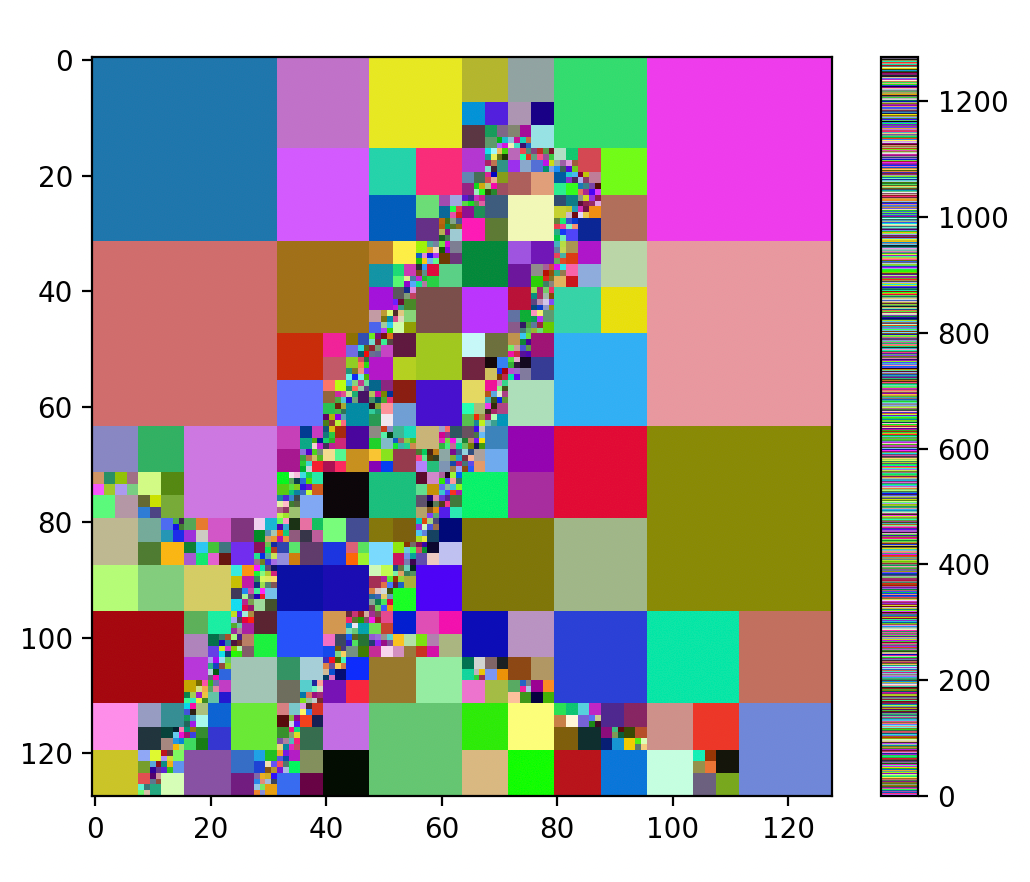
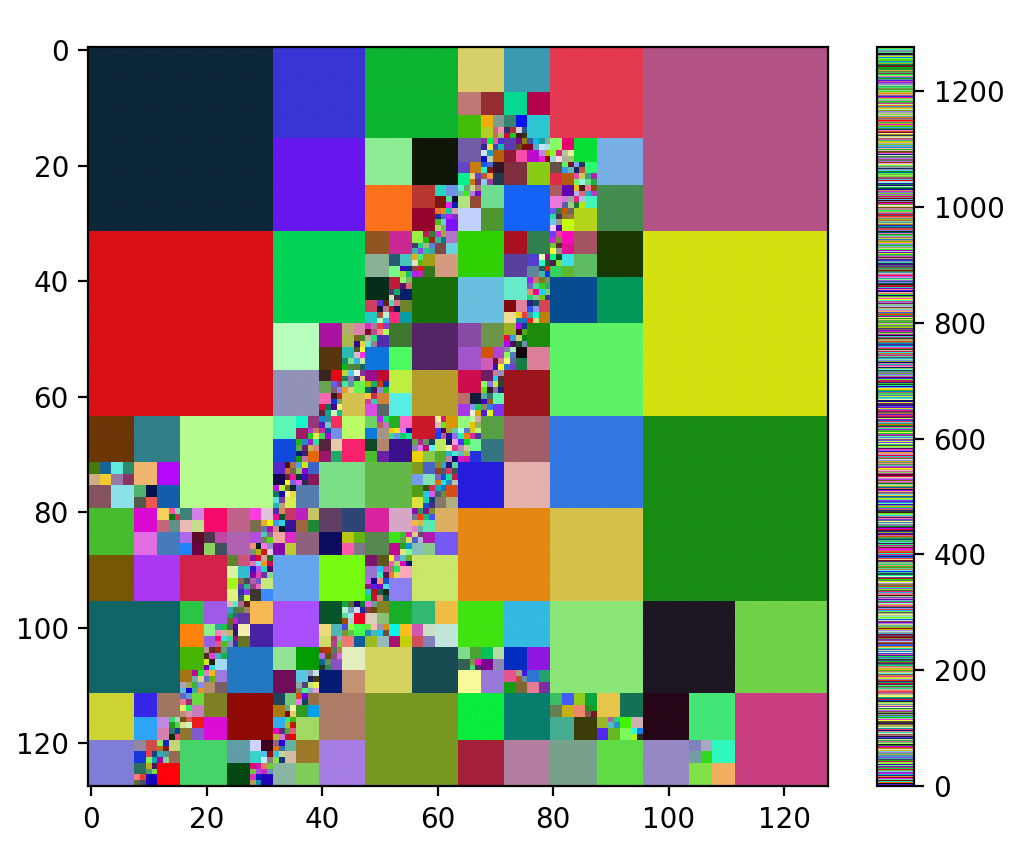
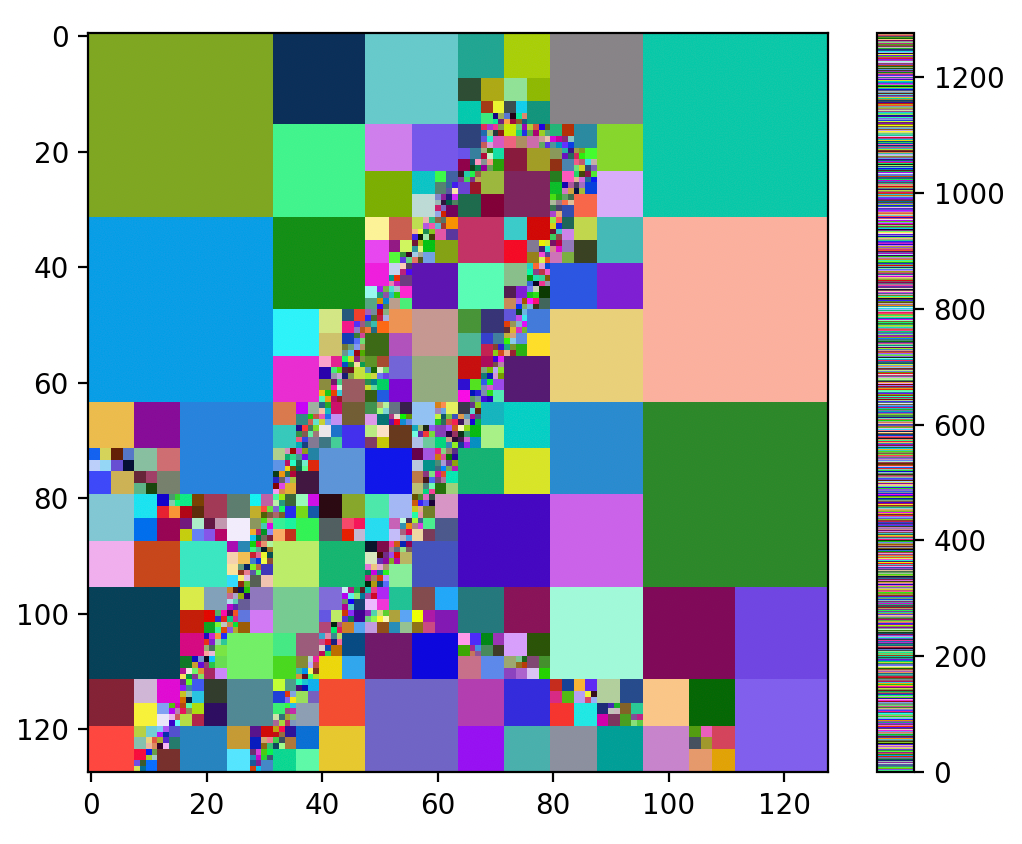
在上述结果中,第一幅图是原图,第二幅图是 kmeans_v1 算法结果,它遍历数据点,然后计算每个点到各类中心的距离,并根据距离来分配类别,不断迭代。第三幅图是 kmeans_v2 结果,这里计算距离的时候,使用矩阵操作,由此算法速度提高。第四幅图是 kmeans_v3 结果,使用了 Scikit-learn 库,这是一个python 机器学习库函数,其中封装了优化的 K-Means 算法的实现。
kmeans_v1 不适合大规模数据处理,kmeans_v2 的向量化矩阵操作大幅提升了计算速度,kmeans_v3 别人已经做好了,同时能够并行优化。
根据三个方法的结果,我们可以看到三种方法在聚类效果上是一致的。
ECC算法结果
连通区域标记方法要注意三个点,第一是它只能识别二值化图像,第二是它要为前景打上标签,第三是邻域的处理。
图像连通区域标记核心思想是识别二值化图像中的所有连通区域,并为每个连通区域分配一个唯一的标签,换句话说,我们的任务就是找到这个二值化图像中的连通区域,给他打上标签,这样我们就可以知道这个图像里有多少个独立的白色区域,以及它们的形状和位置。
其代码实现分成三个步骤,首先进行第一次扫描,遍历图像像素点,如果是0(黑色),那就直接跳过,如果是1(白色),那么看它旁边的格子(上、左上、左、右上)有没有标签,如果周围没有标签,那么就给他分配一个新标签,如果周围有标签,那么就归到这个最小的标签中作为它的标签,并记录哪些标签代表同一个区域。然后整理区域之间的关系,合并相临近且相同的区域,并合并标号。然后我们再进行第二次扫描,更新每个像素点标签,完成最终标记,这样每个连通区域像素点标号就是唯一的。
首先还是哪一套库函数导进来,如下
import numpy as np
import matplotlib.image as mpimg
import time
import seg_tools首先定义一个根查找函数,用来找最终根标签,这样说肯定不理解,我们用一个例子来解释它的工作。
比如说我们现在有一个等价关系表 T = [0, 1, 2, 3, 3, 3],他一共有六个标签,分别是标签0 标签1 标签2 标签3 标签4 标签5,并且标签0 1 2 是它自己本身的根: T[0] = 0, T[1] = 1, T[2] = 2 ,标签3 是标签4 5 的根 T[4] = 3, T[5] = 3
下面我们要找标签5 的根,因此调用函数形式为 root(5, T),具体流程如下:
首先初始化 r = 5,然后检查 T[r] 对应的标签值, T[r]=T[5] = 3 \neq 5 ,这说明 T[r] 前面还有父标签,继续往前找,检查发现 T[3] = 3 ,那么就找到标签 5 的根是 3 。
好比现在搞生化危机,做僵尸鉴定,有的是母体,有的是感染体,正常来讲母体的外表皮DNA和内核DNA是一样的,即 T[0] = 0, T[1] = 1, T[2] = 2 这种情况,感染体他外面是人类DNA,但是实际上它深层次真正DNA上来源母体DNA,但是,它就会出现 T[5] = 3 \neq 5 这样的情况,也就是它表明上的DNA值 = 5,但是它核心DNA值 = 3,说明他就是个感染品,要继续找到他的母体,只需要找到DNA值等于 3 的那个母体就可以了
现在原理搞明白了,我们就要写代码完成这个工作。
# 定义根查找函数,用于解析等价关系
def root(t, T): # t 是当前需要查找根的标签值 T是等价关系表,用于储存标签的父子关系
"""
查找等价关系表 T 中与 t 对应的根节点。
T 是一个数组,每个位置存储了当前标签的根标签。
"""
r = t # 刚开始的时候,假设 t 是根节点
while T[r] != r: # 如果当前标签r 的父标签不是根节点,说明还有父标签,继续查找。否则说明r就是根节点,就退出循环
r = T[r] # 那么就顺着等价关系找到根节点
return r # 返回根节点的索引后面我们就要写 连通组件标记函数部分了,首先我们要进行的一个操作是增加边界,因为我们要访问邻域,最边上那一排像素邻域不完整,这样代码就报错,所以我们给图像加一圈0,单纯为了代码能正常运行而已,并不改变结果。
# 定义连通组件标记函数
def label(I):
"""
输入:
I - 二值化图像 0 和 1 ,表示前景和背景
输出:
标记后的图像,其中每个连通区域有唯一的标签值
"""
dim_y, dim_x = np.shape(I) # 获取输入图像的行数和列数
# 创建带边框的扩展矩阵,避免边界问题
Ia = np.zeros((dim_y + 2, dim_x + 2), dtype=int) # 比原图像在宽和高方向各多扩展2个像素,避免后续访问邻域的时候出界
Ia[1:1 + dim_y, 1:1 + dim_x] = I # 将输入图像嵌入到扩展矩阵中
T = [0] # 等价关系表,初始包含一个值0,T[i] 表示标签 i 的根标签
cpt = 1 # 初始化标签计数器,从1开始分配标签(0表示背景)这里除了上面加边界这个要点外,还需要注意,这里初始化了等价关系表 T ,并且初始化了标签计数器,这个标签计数器的作用是,比如说找到了一个前景个体,给他标1 ,就是用这个标签计数器cpt 幅值的,然后把 cpt +1 变成 2 了,下次再找到第二个个体,给他标 2 的时候接着用 cpt 赋值。
下面我们要进行两次扫描操作,第一次扫描要搜索邻域,建立等价关系。
# 第一次扫描:分配临时标签并建立等价关系
for y in range(1, 1 + dim_y): # 遍历图像的每一行
for x in range(1, 1 + dim_x): # 遍历图像的每一列
if Ia[y, x]: # 当前像素为前景
# 获取当前像素邻域(左上、正上、右上、左)的标签
t = [Ia[y - 1, x - 1], Ia[y - 1, x], Ia[y - 1, x + 1], Ia[y, x - 1]] # 检查邻域
m = 0 # 初始化最小标签,表示目前还未找到任何有效的邻域标签
for k in range(0, 4): # 遍历邻域标签
if t[k]: # 如果邻域中存在前景像素,如果是1则是前景像素,如果是0则为背景
t[k] = root(t[k], T) # 查找根标签
if m == 0: # 如果是第一次,则把当前找到的根标签送给m
m = t[k]
else:
m = min(m, t[k]) # 如果不是第一次,则笔记之前找到的根标签和这次找到的根标签哪个最小
if m == 0: # 如果是第一次,则把新标签分给像素
Ia[y, x] = cpt # 分配新标签
T.append(cpt)
cpt += 1
else: # 邻域中有标签
Ia[y, x] = m
for k in range(0, 4): # 更新等价关系
if t[k] and t[k] != m:
T[t[k]] = m
print(cpt)首先我们要对每个像素都要处理,所以要遍历行遍历列,于此同时,我们只处理前景像素,前景为1 背景为0,所以只有前景像素可以进入循环。随后我们检查当前像素的邻域,为什么要看 左上、正上、右上、左 这个邻域呢?因为像素处理是从左到右自上而下的,当处理到当前像素的时候,上面那一排和左边的处理完了,后面的还没处理,所以我们检查已经处理完的邻域。然后我们挨个找根标签, T[0] T[1] T[2] T[3]他们的根标签都要找出来,就用到之前的 root 函数了,然后找到最小的根标签。
如果邻域中有标签,选择最小的根标签分配给当前像素,如果邻域中没有标签,分配一个新的标签给当前像素。如果当前像素的多个邻域有不同标签,更新这些标签之间的等价关系。在等价关系表 T 中记录这些标签的父子关系,确保它们能被归为同一个根标签。
下面我们进行第二次扫描,解析等价关系表,遍历整个图像,将每个像素的标签替换为等价关系解析后的最终根标签。
# 第二次扫描:解析等价关系并更新标签
for i in range(0, len(T)):
if T[i] == i:
T[i] = cpt
cpt = cpt + 1
else:
T[i] = T[T[i]]
print(cpt)
for y in range(1, 1 + dim_y):
for x in range(1, 1 + dim_x):
Ia[y, x] = T[Ia[y, x]]
return Ia[1:1 + dim_y, 1:1 + dim_x]完整代码如下:
import numpy as np
import matplotlib.image as mpimg
import time
import seg_tools
# 外部自定义函数,要初始化一下
seg_tools.init()
# 定义根查找函数,用于解析等价关系
def root(t, T): # t 是当前需要查找根的标签值 T是等价关系表,用于储存标签的父子关系
"""
查找等价关系表 T 中与 t 对应的根节点。
T 是一个数组,每个位置存储了当前标签的根标签。
"""
r = t # 刚开始的时候,假设 t 是根节点
while T[r] != r: # 如果当前标签r 的父标签不是根节点,说明还有父标签,继续查找。否则说明r就是根节点,就退出循环
r = T[r] # 那么就顺着等价关系找到根节点
return r # 返回根节点的索引
# 定义连通组件标记函数
def label(I):
"""
输入:
I - 二值化图像 0 和 1 ,表示前景和背景
输出:
标记后的图像,其中每个连通区域有唯一的标签值
"""
dim_y, dim_x = np.shape(I) # 获取输入图像的行数和列数
# 创建带边框的扩展矩阵,避免边界问题
Ia = np.zeros((dim_y + 2, dim_x + 2), dtype=int) # 比原图像在宽和高方向各多扩展2个像素,避免后续访问邻域的时候出界
Ia[1:1 + dim_y, 1:1 + dim_x] = I # 将输入图像嵌入到扩展矩阵中
T = [0] # 等价关系表,初始包含一个值0,T[i] 表示标签 i 的根标签
cpt = 1 # 初始化标签计数器,从1开始分配标签(0表示背景)
# 第一次扫描:分配临时标签并建立等价关系
for y in range(1, 1 + dim_y): # 遍历图像的每一行
for x in range(1, 1 + dim_x): # 遍历图像的每一列
if Ia[y, x]: # 当前像素为前景
# 获取当前像素邻域(左上、正上、右上、左)的标签
t = [Ia[y - 1, x - 1], Ia[y - 1, x], Ia[y - 1, x + 1], Ia[y, x - 1]] # 检查邻域
m = 0 # 初始化最小标签,表示目前还未找到任何有效的邻域标签
for k in range(0, 4): # 遍历邻域标签
if t[k]: # 如果邻域中存在前景像素,如果是1则是前景像素,如果是0则为背景
t[k] = root(t[k], T) # 查找根标签
if m == 0: # 如果是第一次,则把当前找到的根标签送给m
m = t[k]
else:
m = min(m, t[k]) # 如果不是第一次,则笔记之前找到的根标签和这次找到的根标签哪个最小
if m == 0: # 如果是第一次,则把新标签分给像素
Ia[y, x] = cpt # 分配新标签
T.append(cpt)
cpt += 1
else: # 邻域中有标签
Ia[y, x] = m
for k in range(0, 4): # 更新等价关系
if t[k] and t[k] != m:
T[t[k]] = m
print(cpt)
# 第二次扫描:解析等价关系并更新标签
for i in range(0, len(T)):
if T[i] == i:
T[i] = cpt
cpt = cpt + 1
else:
T[i] = T[T[i]]
print(cpt)
for y in range(1, 1 + dim_y):
for x in range(1, 1 + dim_x):
Ia[y, x] = T[Ia[y, x]]
return Ia[1:1 + dim_y, 1:1 + dim_x]
# 主逻辑
if __name__ == "__main__":
# 读取图像
I = mpimg.imread('alphabet.bmp')
# 确保图像为二值化(转换为0和1)
binary_image = np.where(I > 0.5, 1, 0)
# 测量运行时间
t1 = time.perf_counter()
for n in range(5): # 运行5次以评估性能
labeled_image = label(binary_image)
t2 = time.perf_counter()
# 输出运行时间
print('Temps :', (t2 - t1) / 5)
# 使用 seg_tools 可视化原始图像和标记结果
seg_tools.draw_uint8(binary_image)
seg_tools.draw_labels(labeled_image)
# 保存结果到文件
seg_labels.save_labels(labeled_image, "output_labels_modified.txt")
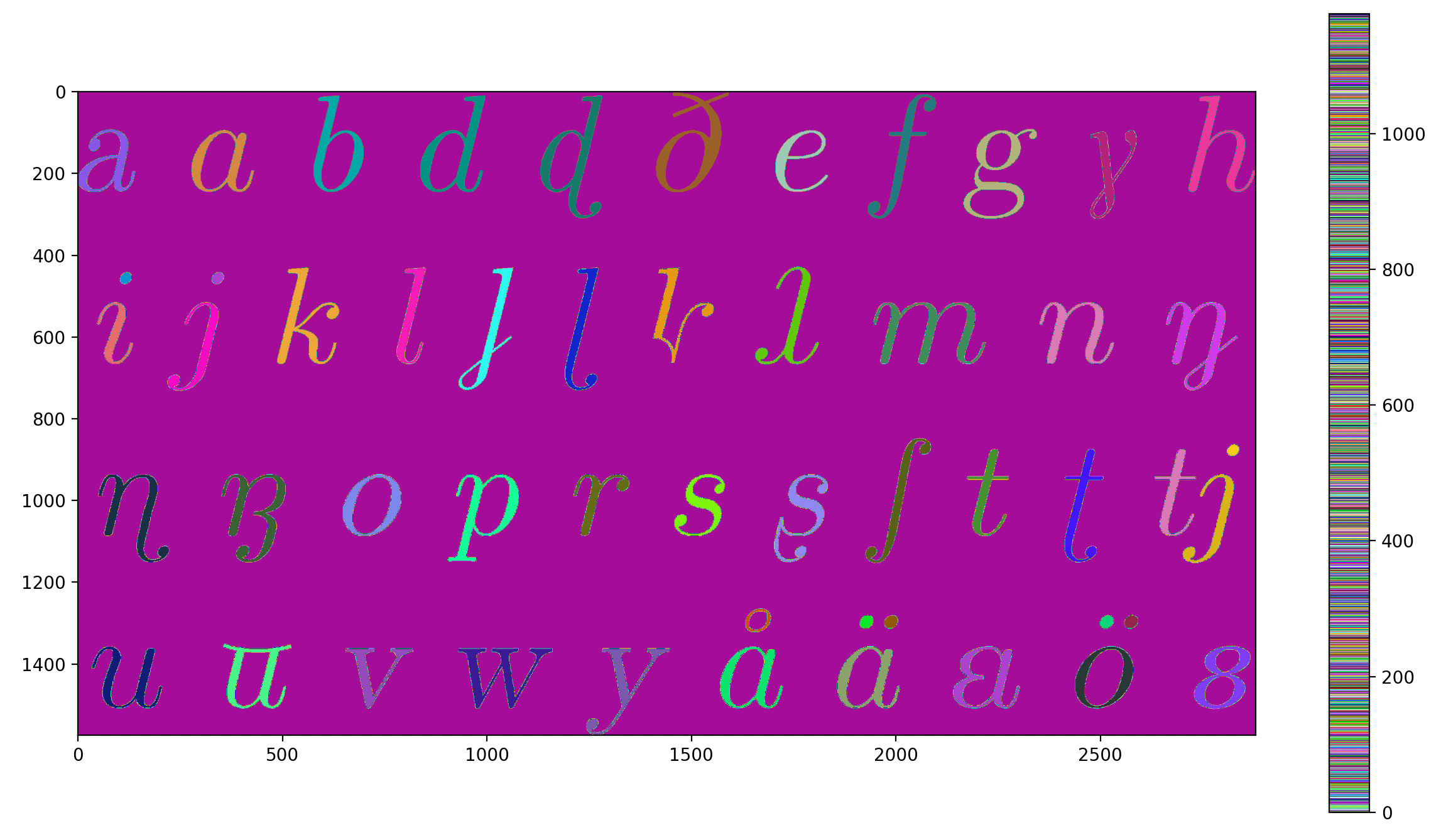
四叉树分割算法结果
将图像分割成多个小的区域,并保证每个区域内部的像素值变化(方差)都比较小(小于阈值t^2),具体有三种实现方式:
quadtree_v1 直接递归分割图像,不断对图像划分为四块,简单的代价是计算量高,每次递归会产生大量的图像切片,内存占用高。
quadtree_v2 不再产生切片,对原图像直接操作,将标签直接写入结果矩阵 L ,不再需要后续合并。
quadtree_v3 进一步减少操作,通过共享结果矩阵 L,直接递归更新。
必要的库函数
import numpy as np
import matplotlib.image as mpimg # 用于加载图像文件
import time # 用于计算运行时间
import seg_tools # 假设该工具包提供图像分割相关功能,如绘制结果等下面是四叉树算法最基础理论版本,它侧重于对子区域迭代循环调用自己来不断划分,最后把子区域拼接起来变成完整图像。
def quadtree_v1_iter(I, E, t):
"""
递归方式实现 Quadtree 图像划分,版本 1。
逐层将图像区域划分为四个子区域,直到满足划分停止条件。
参数:
I: 当前图像(或子图像)区域,二维数组。
E: 当前标记编号(整数),用于标记每个区域。
t: 划分阈值,当区域方差小于 t^2 时停止划分。
返回:
L: 当前区域的标记矩阵,与 I 同尺寸。
E: 更新后的标记编号,供后续区域使用。
"""
dim_y, dim_x = np.shape(I) # 获取当前区域的高度(行数)和宽度(列数)然后我们判断是否满足分割条件,也就是靠看方差来决定,如果区域内方差大,说明区域内像素变化大,就得分割。
# 检查停止条件:
# 1. 如果当前区域的方差 <= 阈值 t^2,说明区域足够均匀。
# 2. 如果当前区域的宽度或高度小于 2,说明已经无法继续划分。
if np.var(I) <= t * t or dim_x < 2 or dim_y < 2:
# 创建一个与当前区域大小相同的矩阵,所有元素标记为 E
L = E * np.ones(np.shape(I), dtype=int) # np.ones() 创建全 1 矩阵,再乘以标记值 E
return L, E + 1 # 返回当前区域的标记矩阵,以及下一个标记编号(E+1)然后我们开始划分区域,由于四叉树算法是一张图画四份,所以我们找到图片中点即可,然后找到四个子区域,继续进行迭代划分,不断分割,一直到不满足条件,最后把划分的区域拼起来
# 如果当前区域不满足停止条件,继续划分成四个子区域
xm = dim_x // 2 # 计算水平中点(列的中间位置)
ym = dim_y // 2 # 计算垂直中点(行的中间位置)
# 对四个子区域递归调用 quadtree_v1_iter()
L1, E = quadtree_v1_iter(I[0:ym, 0:xm], E, t) # 左上子区域
L2, E = quadtree_v1_iter(I[0:ym, xm:dim_x], E, t) # 右上子区域
L3, E = quadtree_v1_iter(I[ym:dim_y, 0:xm], E, t) # 左下子区域
L4, E = quadtree_v1_iter(I[ym:dim_y, xm:dim_x], E, t) # 右下子区域
# 将四个子区域的标记矩阵拼接成完整的标记矩阵 L
# np.concatenate(axis=1) 用于沿水平方向拼接矩阵
# np.concatenate(axis=0) 用于沿垂直方向拼接矩阵
L5 = np.concatenate((L1, L2), axis=1) # 拼接左上和右上子区域,形成上半部分
L6 = np.concatenate((L3, L4), axis=1) # 拼接左下和右下子区域,形成下半部分
L = np.concatenate((L5, L6), axis=0) # 将上半部分和下半部分拼接,形成完整区域
return L, E # 返回完整的标记矩阵和更新后的标记编号现在递归函数已经写好了,下面这个入口函数不是必要的,单纯好看。
def quadtree_v1(I, t):
"""
Quadtree 算法版本 1 的入口函数。
参数:
I: 输入图像(二维数组)。
t: 阈值,当区域方差小于 t^2 时停止划分。
返回:
L: 图像的标记矩阵。
E: 最终的标记编号总数。
"""
return quadtree_v1_iter(I, 0, t) # 从标记编号 0 开始递归划分图像下面我们看第二个版本的四叉树算法,它的不同之处是,直接输入子区域左边,这样的目的是直接在原图片上找坐标,根据坐标定点爆破处理区域,核心没变。
def quadtree_v2_iter(I, x1, y1, x2, y2, L, E, t):
"""
显式边界方式实现 Quadtree 图像划分,版本 2。
通过传递子区域的边界坐标(x1, y1, x2, y2)避免子矩阵切片操作。
参数:
I: 输入图像。
x1, y1: 子区域左上角坐标。
x2, y2: 子区域右下角坐标。
L: 标记矩阵,用于存储划分结果。
E: 当前标记编号。
t: 划分阈值。
返回:
L: 更新后的标记矩阵。
E: 更新后的标记编号。
"""
# 计算当前子区域的宽度和高度
dim_x = x2 + 1 - x1
dim_y = y2 + 1 - y1
# 检查停止条件(与版本 1 类似)
if np.var(I[y1:y2+1, x1:x2+1]) <= t * t or dim_x < 2 or dim_y < 2:
# 将子区域标记为当前编号 E
L[y1:y2+1, x1:x2+1] = E * np.ones((dim_y, dim_x), dtype=int)
return L, E + 1还是要找到图像中点,然后把四个区域坐标写出来。
# 如果不满足停止条件,划分成四个子区域
xm = (x1 + x2) // 2 # 水平中点
ym = (y1 + y2) // 2 # 垂直中点
# 四个子区域的坐标范围
x_l = [x1, xm + 1, x1, xm + 1] # 子区域左上角 x 坐标
x_2 = [xm, x2, xm, x2] # 子区域右下角 x 坐标
y_l = [y1, y1, ym + 1, ym + 1] # 子区域左上角 y 坐标
y_2 = [ym, ym, y2, y2] # 子区域右下角 y 坐标
# 依次递归处理每个子区域
for n in range(4):
L, E = quadtree_v2_iter(I, x_l[n], y_l[n], x_2[n], y_2[n], L, E, t)
return L, E # 返回标记矩阵和更新后的标记编号入口函数如下,同理不是必要的。
def quadtree_v2(I, t):
"""
Quadtree 算法版本 2 的入口函数。
参数:
I: 输入图像。
t: 阈值。
返回:
L: 图像的标记矩阵。
E: 最终的标记编号总数。
"""
dim_y, dim_x = np.shape(I) # 获取图像尺寸
L = np.zeros((dim_y, dim_x), dtype=int) # 初始化标记矩阵为全 0
return quadtree_v2_iter(I, 0, 0, dim_x - 1, dim_y - 1, L, 0, t)第三个版本 不解释了,没玩明白。完整代码如下:
import numpy as np
import matplotlib.image as mpimg # 用于加载图像文件
import time # 用于计算运行时间
import seg_tools # 假设该工具包提供图像分割相关功能,如绘制结果等
# ---------------------------
# Quadtree 算法版本 1
# ---------------------------
def quadtree_v1_iter(I, E, t):
"""
递归方式实现 Quadtree 图像划分,版本 1。
逐层将图像区域划分为四个子区域,直到满足划分停止条件。
参数:
I: 当前图像(或子图像)区域,二维数组。
E: 当前标记编号(整数),用于标记每个区域。
t: 划分阈值,当区域方差小于 t^2 时停止划分。
返回:
L: 当前区域的标记矩阵,与 I 同尺寸。
E: 更新后的标记编号,供后续区域使用。
"""
dim_y, dim_x = np.shape(I) # 获取当前区域的高度(行数)和宽度(列数)
# 检查停止条件:
# 1. 如果当前区域的方差 <= 阈值 t^2,说明区域足够均匀。
# 2. 如果当前区域的宽度或高度小于 2,说明已经无法继续划分。
if np.var(I) <= t * t or dim_x < 2 or dim_y < 2:
# 创建一个与当前区域大小相同的矩阵,所有元素标记为 E
L = E * np.ones(np.shape(I), dtype=int) # np.ones() 创建全 1 矩阵,再乘以标记值 E
return L, E + 1 # 返回当前区域的标记矩阵,以及下一个标记编号(E+1)
# 如果当前区域不满足停止条件,继续划分成四个子区域
xm = dim_x // 2 # 计算水平中点(列的中间位置)
ym = dim_y // 2 # 计算垂直中点(行的中间位置)
# 对四个子区域递归调用 quadtree_v1_iter()
L1, E = quadtree_v1_iter(I[0:ym, 0:xm], E, t) # 左上子区域
L2, E = quadtree_v1_iter(I[0:ym, xm:dim_x], E, t) # 右上子区域
L3, E = quadtree_v1_iter(I[ym:dim_y, 0:xm], E, t) # 左下子区域
L4, E = quadtree_v1_iter(I[ym:dim_y, xm:dim_x], E, t) # 右下子区域
# 将四个子区域的标记矩阵拼接成完整的标记矩阵 L
# np.concatenate(axis=1) 用于沿水平方向拼接矩阵
# np.concatenate(axis=0) 用于沿垂直方向拼接矩阵
L5 = np.concatenate((L1, L2), axis=1) # 拼接左上和右上子区域,形成上半部分
L6 = np.concatenate((L3, L4), axis=1) # 拼接左下和右下子区域,形成下半部分
L = np.concatenate((L5, L6), axis=0) # 将上半部分和下半部分拼接,形成完整区域
return L, E # 返回完整的标记矩阵和更新后的标记编号
def quadtree_v1(I, t):
"""
Quadtree 算法版本 1 的入口函数。
参数:
I: 输入图像(二维数组)。
t: 阈值,当区域方差小于 t^2 时停止划分。
返回:
L: 图像的标记矩阵。
E: 最终的标记编号总数。
"""
return quadtree_v1_iter(I, 0, t) # 从标记编号 0 开始递归划分图像
# ---------------------------
# Quadtree 算法版本 2
# ---------------------------
def quadtree_v2_iter(I, x1, y1, x2, y2, L, E, t):
"""
显式边界方式实现 Quadtree 图像划分,版本 2。
通过传递子区域的边界坐标(x1, y1, x2, y2)避免子矩阵切片操作。
参数:
I: 输入图像。
x1, y1: 子区域左上角坐标。
x2, y2: 子区域右下角坐标。
L: 标记矩阵,用于存储划分结果。
E: 当前标记编号。
t: 划分阈值。
返回:
L: 更新后的标记矩阵。
E: 更新后的标记编号。
"""
# 计算当前子区域的宽度和高度
dim_x = x2 + 1 - x1
dim_y = y2 + 1 - y1
# 检查停止条件(与版本 1 类似)
if np.var(I[y1:y2+1, x1:x2+1]) <= t * t or dim_x < 2 or dim_y < 2:
# 将子区域标记为当前编号 E
L[y1:y2+1, x1:x2+1] = E * np.ones((dim_y, dim_x), dtype=int)
return L, E + 1
# 如果不满足停止条件,划分成四个子区域
xm = (x1 + x2) // 2 # 水平中点
ym = (y1 + y2) // 2 # 垂直中点
# 四个子区域的坐标范围
x_l = [x1, xm + 1, x1, xm + 1] # 子区域左上角 x 坐标
x_2 = [xm, x2, xm, x2] # 子区域右下角 x 坐标
y_l = [y1, y1, ym + 1, ym + 1] # 子区域左上角 y 坐标
y_2 = [ym, ym, y2, y2] # 子区域右下角 y 坐标
# 依次递归处理每个子区域
for n in range(4):
L, E = quadtree_v2_iter(I, x_l[n], y_l[n], x_2[n], y_2[n], L, E, t)
return L, E # 返回标记矩阵和更新后的标记编号
def quadtree_v2(I, t):
"""
Quadtree 算法版本 2 的入口函数。
参数:
I: 输入图像。
t: 阈值。
返回:
L: 图像的标记矩阵。
E: 最终的标记编号总数。
"""
dim_y, dim_x = np.shape(I) # 获取图像尺寸
L = np.zeros((dim_y, dim_x), dtype=int) # 初始化标记矩阵为全 0
return quadtree_v2_iter(I, 0, 0, dim_x - 1, dim_y - 1, L, 0, t)
# ---------------------------
# Quadtree 算法版本 3
# ---------------------------
def quadtree_v3_iter(I, E, L, t):
"""
使用共享标记矩阵方式实现 Quadtree 图像划分,版本 3。
参数:
I: 当前图像区域。
E: 当前标记编号。
L: 全局共享的标记矩阵。
t: 划分阈值。
返回:
E: 更新后的标记编号。
"""
dim_y, dim_x = np.shape(I) # 获取当前区域的尺寸
# 检查停止条件
if np.var(I) <= t * t or dim_x < 2 or dim_y < 2:
L[:, :] = E * np.ones((dim_y, dim_x)) # 标记整个区域
return E + 1 # 返回更新后的标记编号
# 划分为四个子区域并递归处理
xm = dim_x // 2
ym = dim_y // 2
E = quadtree_v3_iter(I[0:ym, 0:xm], E, L[0:ym, 0:xm], t)
E = quadtree_v3_iter(I[0:ym, xm:dim_x], E, L[0:ym, xm:dim_x], t)
E = quadtree_v3_iter(I[ym:dim_y, 0:xm], E, L[ym:dim_y, 0:xm], t)
E = quadtree_v3_iter(I[ym:dim_y, xm:dim_x], E, L[ym:dim_y, xm:dim_x], t)
return E
def quadtree_v3(I, t):
"""
Quadtree 算法版本 3 的入口函数。
"""
L = np.zeros(np.shape(I), dtype=int) # 初始化标记矩阵
E = quadtree_v3_iter(I, 0, L, t) # 从标记编号 0 开始
return L, E
区域生长算法(Region Growing Algorithm)
基于像素相似性的分割方法,算法从一组初始种子点开始,将与这些种子点相似的像素加入到同一分割区域中,直到不再有符合条件的像素。
import numpy as np
from operator import itemgetter
import matplotlib.image as mpimg # 用于加载图像文件
import time # 用于运行时间测量
import seg_tools # 假设提供绘制图像和标签等工具
import seg_regiongrowing # 假设这是实现区域增长算法的模块老熟人了,下面给出三个手选的初始区域
# 手动设置初始标记区域
L[40:48, 60:70] = 1 # 第一个初始区域,标记为 1
L[110:120, 70:80] = 2 # 第二个初始区域,标记为 2
L[0:10, 0:10] = 3 # 第三个初始区域,标记为 3下面给出区域生长算法版本1,但是在这之前,我们需要定义一个找邻居函数,也就是说我们要找到像素的邻域并且把邻居添加到待处理列表中。
def add_neighbours(V, L, dim_x, dim_y, x, y, dx, dy):
"""
将像素 (x, y) 的邻域像素添加到候选列表 V 中。
仅添加未被标记的邻域像素。
参数:
V: 候选像素列表,存储待处理的像素。
L: 当前的标记矩阵,记录哪些像素已经被标记。
dim_x, dim_y: 图像的宽度和高度。
x, y: 当前像素的坐标。
dx, dy: 描述邻域方向的偏移量列表(dx 和 dy 共同定义邻域)。
"""
for i in range(len(dx)): # 遍历所有邻域方向
xx = x + dx[i] # 计算邻域像素的 x 坐标
yy = y + dy[i] # 计算邻域像素的 y 坐标
# 检查邻域像素是否在图像范围内,并且尚未被标记
if 0 <= xx < dim_x and 0 <= yy < dim_y and L[yy, xx] == 0:
V.append([xx, yy]) # 将邻域像素添加到候选列表更通俗的来讲,算法现在找到了一个像素,然后要从这个像素入手访问它的邻居,问问他们青年大学习做了没有?还没做的那就放到候选列表 V 中,一会再来处理这批人。与之前处理邻域方法不同的是,这里使用 dx[i] dy[i] 来计算像素邻域,在后面我们会看到它的邻域是上下左右,如果更精细一点就把对角线也加进来,同时邻域不能超出图像范围。
def regiongrowing_v1(I, Lin, threshold, neighbourhood):
"""
区域增长算法的基本实现(版本 1)。
处理单一区域,使用种子像素和阈值控制增长。
参数:
I: 输入图像(二维数组)。
Lin: 初始标记矩阵,非零值表示种子区域。
threshold: 阈值,用于判定邻域像素是否可以加入区域。
neighbourhood: 邻域类型(4 邻域或 8 邻域)。
返回:
Lout: 输出的标记矩阵。
"""
dim_y, dim_x = np.shape(Lin) # 获取图像尺寸(高度和宽度)
# 根据邻域类型设置方向偏移
if neighbourhood == 4: # 4 邻域:上下左右
dx = [-1, 0, 0, 1] # x 方向偏移
dy = [0, -1, 1, 0] # y 方向偏移
else: # 8 邻域:包括对角线
dx = [-1, 0, 1, 1, 1, 0, -1, -1]
dy = [0, -1, -1, 0, 1, 1, 1, -1]这里邻域搭建好了,下面我们要做一些初始化准备
# 初始化标记矩阵(复制输入矩阵)
Lout = np.copy(Lin)
V = list() # 候选像素列表,存储待处理的邻域像素
region_nb = 0 # 区域内像素数量
region_sum = 0 # 区域内像素灰度值总和这里的 Lout 就是一个地图,标记了哪些地方去过哪些地方没去过,主要是我们不能直接拿输入数据 Lint 来用,不然在原始地图上面写写画画就把地图画坏了,因此我们复制了一份地图,在复制品上标记。 v 的作用就是任务清单,待处理的邻域像素一点点处理完,一直到清单划空。后面那两个是算区域平均值用的。
# 遍历初始标记矩阵,将种子点的邻域加入候选像素列表
for y in range(dim_y):
for x in range(dim_x):
if Lin[y, x]: # 如果该像素属于种子区域
add_neighbours(V, Lout, dim_x, dim_y, x, y, dx, dy) # 添加邻域像素
region_nb += 1 # 计入种子区域的像素数量
region_sum += I[y, x] # 累加种子区域的灰度值
# 开始区域增长过程
while len(V): # 当候选像素列表不为空时
[x, y] = V.pop(0) # 从候选列表中取出第一个像素
# 如果像素未被标记,且与区域平均灰度差小于阈值,则将其加入区域
if Lout[y, x] == 0 and abs(I[y, x] - region_sum / region_nb) < threshold:
region_nb += 1 # 更新区域像素数量
region_sum += I[y, x] # 更新区域灰度总和
Lout[y, x] = 1 # 将该像素标记为区域的一部分
add_neighbours(V, Lout, dim_x, dim_y, x, y, dx, dy) # 添加新像素的邻域
return Lout # 返回最终的标记矩阵这里我们正式开始了区域增长过程,首先遍历行遍历列,如果找到了种子区域,那么就找它的邻域像素,然后把种子区域有多少个像素值以及像素值总和保存下来,然后我们就针对 V 开始处理了,我们打比方现在正在种花,我们现在有了一个代办清单,里面全是可以种花的空地,然后我们按照清单里的顺序一个个处理,看看这块空地的土壤肥沃度(灰度值)和种子区域平均肥沃度(灰度值)是不是差不多,如果差不多说明这花可以种在这,并且更新这块区域的土壤肥沃度,继续把他的邻居加到清单里。在我们结束这个迭代过程后,我们得到了一个更新后的地图 Lout 标记了不同区域种了哪些花。
然后我们实现第二个版本的区域生长算法,其不同之处在于,有很多个园丁在同一片土地种花,每个人管自己的区域,互不打扰,每个区域都独立统计自己的候选像素列表。
def regiongrowing_v2(I, Lin, threshold, neighbourhood):
# 中间部分省略
# 为每个种子区域初始化候选列表、像素数量和灰度总和
V = [[list(), 0, 0] for _ in range(nb)]
# 遍历初始标记矩阵,初始化种子区域的信息
for y in range(dim_y):
for x in range(dim_x):
no = Lin[y, x] # 当前像素的区域编号
if no: # 如果属于某个种子区域
add_neighbours(V[no - 1][0], Lout, dim_x, dim_y, x, y, dx, dy) # 添加邻域像素
V[no - 1][1] += 1 # 更新区域像素数量
V[no - 1][2] += I[y, x] # 更新区域灰度总和
# 区域增长过程,部分重复代码省略
[x, y] = V[i][0].pop(0) # 从候选列表中取出第一个像素
if Lout[y, x] == 0 and abs(I[y, x] - V[i][2] / V[i][1]) < threshold:
# 如果像素未被标记且满足区域增长条件
V[i][1] += 1 # 更新区域像素数量
V[i][2] += I[y, x] # 更新区域灰度总和
Lout[y, x] = i + 1 # 将像素标记为当前区域
add_neighbours(V[i][0], Lout, dim_x, dim_y, x, y, dx, dy) # 添加新邻域像素
return Lout # 返回最终的标记矩阵完整代码如下:
import numpy as np
from operator import itemgetter
import matplotlib.image as mpimg # 用于加载图像文件
# -----------------------
# 辅助函数:添加邻域像素
# -----------------------
def add_neighbours(V, L, dim_x, dim_y, x, y, dx, dy):
"""
将像素 (x, y) 的邻域像素添加到候选列表 V 中。
仅添加未被标记的邻域像素。
参数:
V: 候选像素列表,存储待处理的像素。
L: 当前的标记矩阵,记录哪些像素已经被标记。
dim_x, dim_y: 图像的宽度和高度。
x, y: 当前像素的坐标。
dx, dy: 描述邻域方向的偏移量列表(dx 和 dy 共同定义邻域)。
"""
for i in range(len(dx)): # 遍历所有邻域方向
xx = x + dx[i] # 计算邻域像素的 x 坐标
yy = y + dy[i] # 计算邻域像素的 y 坐标
# 检查邻域像素是否在图像范围内,并且尚未被标记
if 0 <= xx < dim_x and 0 <= yy < dim_y and L[yy, xx] == 0:
V.append([xx, yy]) # 将邻域像素添加到候选列表
# ---------------------------
# 区域增长算法版本 1
# ---------------------------
def regiongrowing_v1(I, Lin, threshold, neighbourhood):
"""
区域增长算法的基本实现(版本 1)。
处理单一区域,使用种子像素和阈值控制增长。
参数:
I: 输入图像(二维数组)。
Lin: 初始标记矩阵,非零值表示种子区域。
threshold: 阈值,用于判定邻域像素是否可以加入区域。
neighbourhood: 邻域类型(4 邻域或 8 邻域)。
返回:
Lout: 输出的标记矩阵。
"""
dim_y, dim_x = np.shape(Lin) # 获取图像尺寸(高度和宽度)
# 根据邻域类型设置方向偏移
if neighbourhood == 4: # 4 邻域:上下左右
dx = [-1, 0, 0, 1] # x 方向偏移
dy = [0, -1, 1, 0] # y 方向偏移
else: # 8 邻域:包括对角线
dx = [-1, 0, 1, 1, 1, 0, -1, -1]
dy = [0, -1, -1, 0, 1, 1, 1, -1]
# 初始化标记矩阵(复制输入矩阵)
Lout = np.copy(Lin)
V = list() # 候选像素列表,存储待处理的邻域像素
region_nb = 0 # 区域内像素数量
region_sum = 0 # 区域内像素灰度值总和
# 遍历初始标记矩阵,将种子点的邻域加入候选像素列表
for y in range(dim_y):
for x in range(dim_x):
if Lin[y, x]: # 如果该像素属于种子区域
add_neighbours(V, Lout, dim_x, dim_y, x, y, dx, dy) # 添加邻域像素
region_nb += 1 # 计入种子区域的像素数量
region_sum += I[y, x] # 累加种子区域的灰度值
# 开始区域增长过程
while len(V): # 当候选像素列表不为空时
[x, y] = V.pop(0) # 从候选列表中取出第一个像素
# 如果像素未被标记,且与区域平均灰度差小于阈值,则将其加入区域
if Lout[y, x] == 0 and abs(I[y, x] - region_sum / region_nb) < threshold:
region_nb += 1 # 更新区域像素数量
region_sum += I[y, x] # 更新区域灰度总和
Lout[y, x] = 1 # 将该像素标记为区域的一部分
add_neighbours(V, Lout, dim_x, dim_y, x, y, dx, dy) # 添加新像素的邻域
return Lout # 返回最终的标记矩阵
# ---------------------------
# 区域增长算法版本 2
# ---------------------------
def regiongrowing_v2(I, Lin, threshold, neighbourhood):
"""
区域增长算法的改进实现(版本 2)。
支持多个区域同时增长,针对每个区域分别维护候选像素队列。
参数:
I: 输入图像(二维数组)。
Lin: 初始标记矩阵,非零值表示多个种子区域。
threshold: 阈值,用于判定邻域像素是否可以加入区域。
neighbourhood: 邻域类型(4 邻域或 8 邻域)。
返回:
Lout: 输出的标记矩阵。
"""
dim_y, dim_x = np.shape(Lin) # 获取图像尺寸(高度和宽度)
# 根据邻域类型设置方向偏移
if neighbourhood == 4: # 4 邻域
dx = [-1, 0, 0, 1]
dy = [0, -1, 1, 0]
else: # 8 邻域
dx = [-1, 0, 1, 1, 1, 0, -1, -1]
dy = [0, -1, -1, 0, 1, 1, 1, -1]
Lout = np.copy(Lin) # 初始化输出标记矩阵
nb = np.max(Lin) # 获取初始标记的最大值(种子区域编号)
# 为每个种子区域初始化候选列表、像素数量和灰度总和
V = [[list(), 0, 0] for _ in range(nb)]
# 遍历初始标记矩阵,初始化种子区域的信息
for y in range(dim_y):
for x in range(dim_x):
no = Lin[y, x] # 当前像素的区域编号
if no: # 如果属于某个种子区域
add_neighbours(V[no - 1][0], Lout, dim_x, dim_y, x, y, dx, dy) # 添加邻域像素
V[no - 1][1] += 1 # 更新区域像素数量
V[no - 1][2] += I[y, x] # 更新区域灰度总和
# 区域增长过程
cpt = nb # 初始化剩余活动区域计数器
while cpt: # 当仍有活动区域时
cpt = 0 # 重置活动区域计数器
for i in range(nb): # 遍历所有种子区域
if len(V[i][0]): # 如果该区域仍有待处理的像素
cpt += 1 # 增加活动区域计数
[x, y] = V[i][0].pop(0) # 从候选列表中取出第一个像素
if Lout[y, x] == 0 and abs(I[y, x] - V[i][2] / V[i][1]) < threshold:
# 如果像素未被标记且满足区域增长条件
V[i][1] += 1 # 更新区域像素数量
V[i][2] += I[y, x] # 更新区域灰度总和
Lout[y, x] = i + 1 # 将像素标记为当前区域
add_neighbours(V[i][0], Lout, dim_x, dim_y, x, y, dx, dy) # 添加新邻域像素
return Lout # 返回最终的标记矩阵import numpy as np
from operator import itemgetter
import matplotlib.image as mpimg # 用于加载图像文件
import time # 用于运行时间测量
import seg_tools # 假设提供绘制图像和标签等工具
import seg_regiongrowing # 假设这是实现区域增长算法的模块
# 初始化工具包
seg_tools.init()
# 加载测试图像
I = mpimg.imread('implant.bmp') # 读取 implant.bmp 图像并存储为数组形式
# 初始化一个标记矩阵 L,形状与图像 I 相同,初始全为 0
L = np.zeros(np.shape(I), dtype=int)
# 手动设置初始标记区域
L[40:48, 60:70] = 1 # 第一个初始区域,标记为 1
L[110:120, 70:80] = 2 # 第二个初始区域,标记为 2
L[0:10, 0:10] = 3 # 第三个初始区域,标记为 3
# 测试 regiongrowing_v1 的运行时间
t1 = time.perf_counter() # 记录起始时间
for n in range(100): # 重复执行 100 次,便于计算平均运行时间
L1 = seg_regiongrowing.regiongrowing_v1(I, L == 2, 30, 4) # 区域增长,针对标记为 2 的区域
t2 = time.perf_counter() # 记录结束时间
print('Temps = ', (t2 - t1) / 100) # 输出平均运行时间
# 测试 regiongrowing_v2 的运行时间
t1 = time.perf_counter()
for n in range(100):
L2 = seg_regiongrowing.regiongrowing_v2(I, L, 30, 8) # 区域增长,考虑 8 邻域连接
t2 = time.perf_counter()
print('Temps = ', (t2 - t1) / 100)
# 可视化原始图像和结果
seg_tools.draw_uint8(I) # 绘制原始图像
seg_tools.draw_labels(L) # 绘制初始标记矩阵
seg_tools.draw_labels(L1) # 绘制 regiongrowing_v1 的结果
seg_tools.draw_labels(L2) # 绘制 regiongrowing_v2 的结果
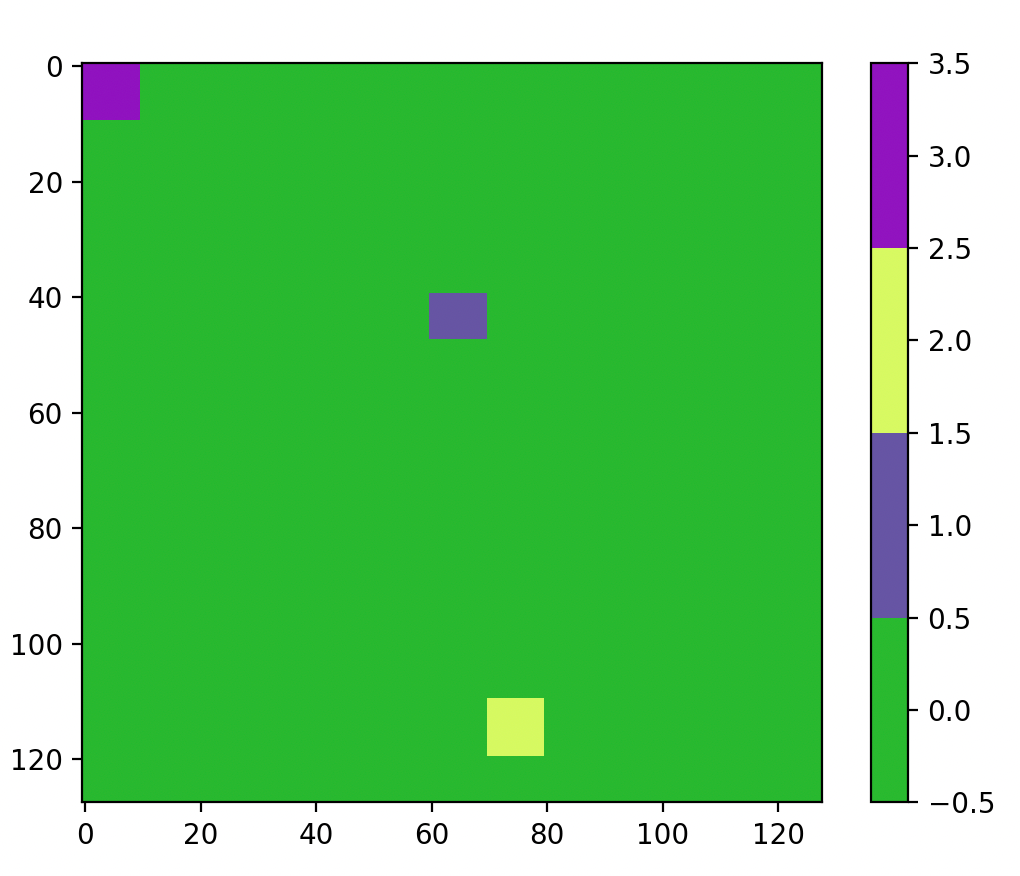
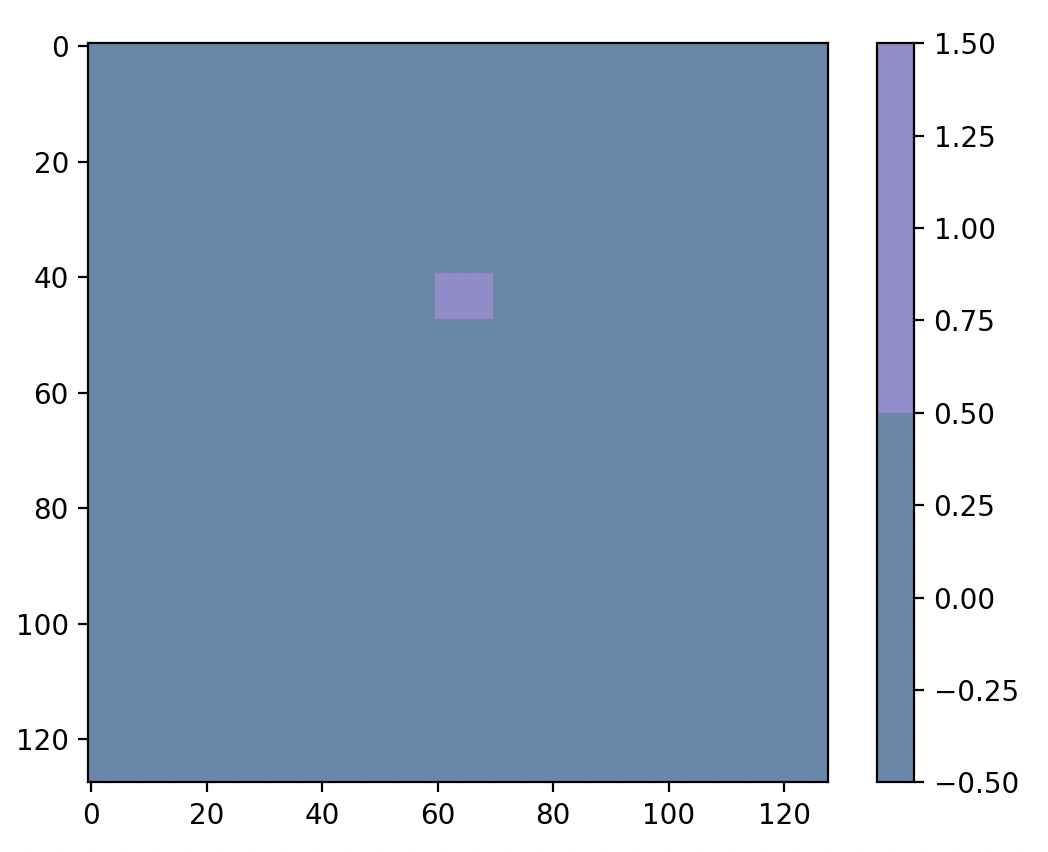
右上角的是初始种子图像,紫色、黄色、蓝色块分别表示三个初始种子区域,作为区域生长的起始位置
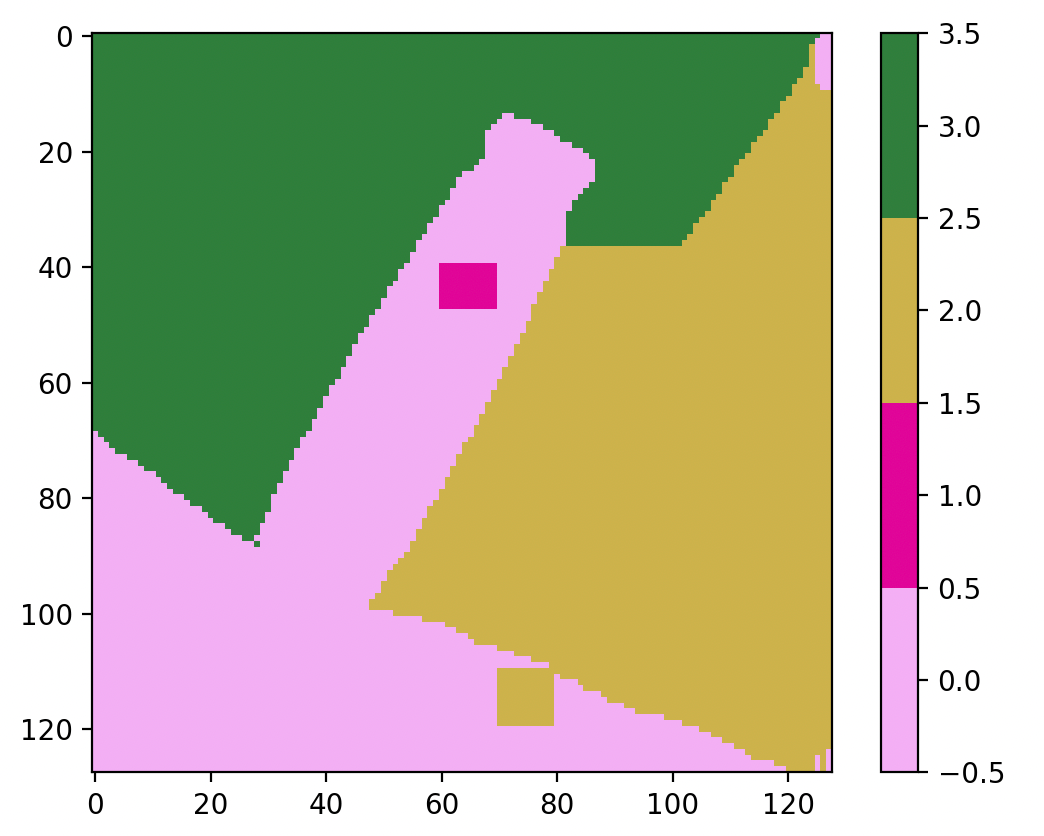
右下角是 regiongrowing_v2 的结果,可以从多个种子点同时扩展,适合更复杂的分割任务。
左下角是 regiongrowing_v1 的结果,v1 只使用了一个初始种子作为扩展,并且还是中间的那个初始种子,最终发现区域生长无法扩展,算法失败。如果 我们选右下角的初始种子来扩展,可以得到以下结果:
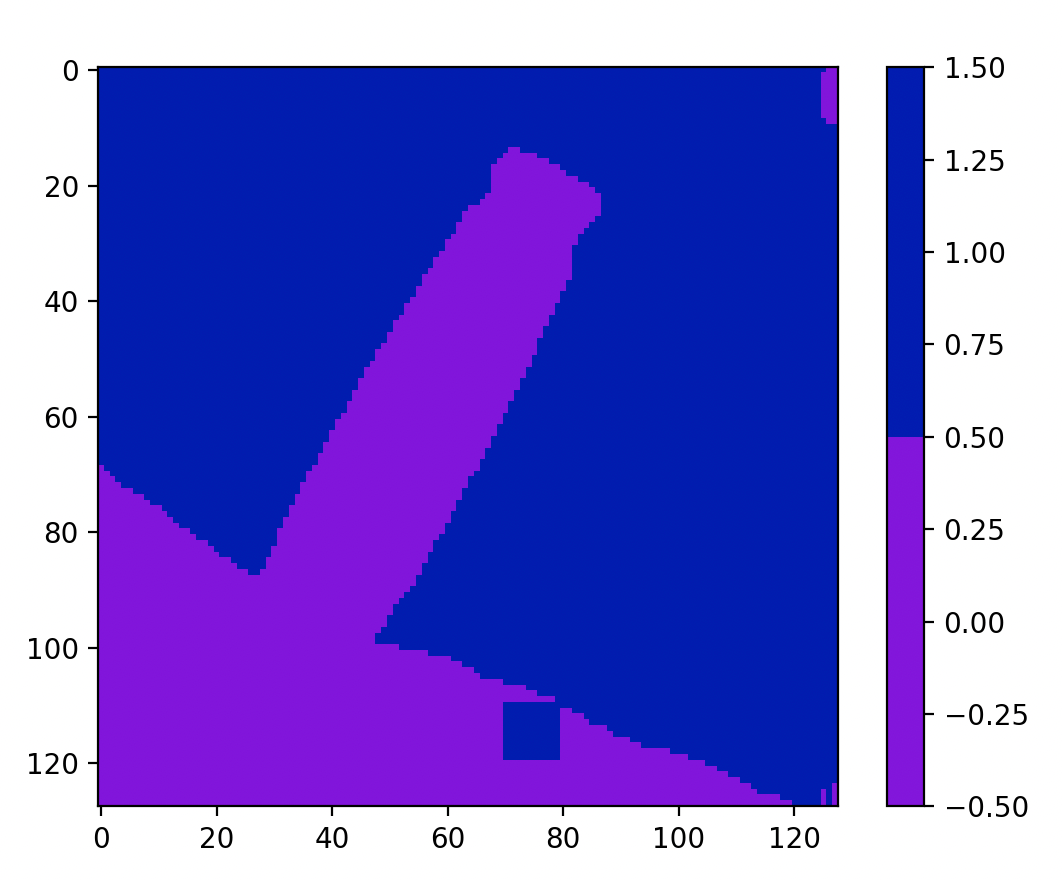
可见还行,最好的当然是三个初始种子一起生长。
SLIC 超像素分割算法
将图像划分为多个超像素区域,算法结合了像素值相似性和空间距离的影响,生成大小均匀、形状规则的分割区域。
import numpy as np
import cv2
import matplotlib.pyplot as plt
import seg_tools # 假设为图像分割工具包,提供绘制功能
import matplotlib.image as mpimg # 用于加载图像文件
import time # 用于计算运行时间老朋友见面倍感亲切,下面我们写一个聚类函数,为了计算每个聚类的中心位置,更新超像素的亮度和坐标信息,其中有一个标记矩阵 L,他就是一张社区地图,它告诉我们每个像素是那个社区的,然后统计每个社区的平均财富值(亮度)。
import numpy as np
import cv2
import matplotlib.pyplot as plt
import seg_tools # 假设为图像分割工具包,提供绘制功能
import matplotlib.image as mpimg # 用于加载图像文件
import time # 用于计算运行时间
# ----------------------------
# 辅助函数:更新聚类中心
# ----------------------------
def clusters(I, L, C):
"""
根据当前的像素分配(L)计算每个聚类的中心信息。
参数:
I: 输入图像(二维数组),灰度图。
L: 当前的标记矩阵,存储每个像素属于哪个聚类。
C: 聚类中心数组,存储每个聚类的 [亮度, x 坐标, y 坐标]。
"""
dim_y, dim_x = np.shape(I) # 获取图像的高度和宽度
nb = np.size(C, 0) # 聚类的数量
C *= 0 # 将聚类中心清零,准备重新计算
cpt = np.zeros((nb, 1)) # 计数器,用于统计每个聚类包含的像素数量
# 遍历所有像素,累加属于每个聚类的亮度和坐标
for y in range(dim_y):
for x in range(dim_x):
Lxy = L[y][x] # 获取像素所属的聚类编号
C[Lxy][0] += I[y][x] # 累加亮度值
C[Lxy][1] += x # 累加 x 坐标
C[Lxy][2] += y # 累加 y 坐标
cpt[Lxy][0] += 1 # 增加该聚类的像素计数
# 计算每个聚类的中心
for i in range(nb):
for k in range(3): # 逐项更新亮度、x 坐标和 y 坐标的平均值
if cpt[i][0]: # 避免除以零
C[i][k] /= cpt[i][0] # 计算平均值上面我们用 C 来作为统计表格,首先肯定弄一张新统计表,然后拿一个计数器 cpt ,将其初始化为0,表示还没统计过任何住户,然后我们遍历走过每个像素,找到其住户编号L[y][x] ,并且记录这位住户的财富值,累加到社区财富总和,把其地址也累加到社区地址总和,其竖起加1 ,表明新统计了一个住户。最后我们计算每个社区的 平均财富(平均亮度值) 和 中心地址(平均坐标),后续要用。
下面我们实现SLIC函数,下面这部分没什么
def SLIC(I, nx, ny, nb_iter, m):
"""
SLIC 超像素分割算法实现。
参数:
I: 输入图像(二维数组),灰度图。
nx: 水平方向的聚类数目。
ny: 垂直方向的聚类数目。
nb_iter: 算法的迭代次数。
m: 距离权重参数(空间和亮度距离的权重平衡因子)。
返回:
L: 输出的标记矩阵,每个像素对应一个聚类编号。
C: 最终的聚类中心信息,包含每个聚类的 [亮度, x 坐标, y 坐标]。
"""
dim_y, dim_x = np.shape(I) # 获取图像的高度和宽度然后我们先给图像划分网格,每个小网格就是一个初始社区,然后我们把表格 C 画好,进行一系列的初始化操作
# 计算每个聚类的初始块大小
sx = dim_x / nx # 水平方向的块大小
sy = dim_y / ny # 垂直方向的块大小
# 生成初始标记矩阵 L,划分为 nx × ny 的网格
X, Y = np.meshgrid(np.arange(0, dim_x), np.arange(0, dim_y)) # 创建像素坐标网格
X = np.floor(X / dim_x * nx).astype(int) # 水平方向的聚类编号
X[X >= nx] = nx - 1 # 修正边界值
Y = np.floor(Y / dim_y * ny).astype(int) # 垂直方向的聚类编号
Y[Y >= ny] = ny - 1 # 修正边界值
L = Y * nx + X # 初始标记矩阵,线性编号
# 初始化聚类中心矩阵 C,每个聚类包含 [亮度, x 坐标, y 坐标]
C = np.zeros((nx * ny, 3))
clusters(I, L, C) # 根据初始分配更新聚类中心信息
# 初始化距离矩阵 D,用于存储每个像素到最近聚类中心的距离
D = np.zeros((dim_y, dim_x)) # 迭代更新聚类分配和中心位置
for i in range(nb_iter):
D.fill(-1) # 重置距离矩阵,-1 表示尚未分配
for k in range(nx * ny): # 遍历每个聚类
l = C[k][0] # 当前聚类的亮度中心
xc = int(C[k][1]) # 当前聚类的 x 坐标中心
yc = int(C[k][2]) # 当前聚类的 y 坐标中心
# 确定搜索区域的边界
x1 = max(xc - int(sx), 0) # 左边界
x2 = min(xc + int(sx), dim_x - 1) # 右边界
y1 = max(yc - int(sy), 0) # 上边界
y2 = min(yc + int(sy), dim_y - 1) # 下边界
# 计算搜索区域内每个像素的亮度距离
D1 = np.abs(I[y1:y2+1, x1:x2+1] - l) # 亮度差距
# 计算空间距离
X_region, Y_region = np.meshgrid(np.arange(x1, x2+1), np.arange(y1, y2+1))
DX = (X_region - xc) / sx # x 坐标归一化距离
DY = (Y_region - yc) / sy # y 坐标归一化距离
D2 = np.sqrt(DX**2 + DY**2) # 空间距离
# 计算综合距离
D12 = D1 + m * D2 # m 为权重参数,平衡亮度和空间的影响
# 更新距离矩阵和标记矩阵
for y in range(y1, y2+1):
for x in range(x1, x2+1):
dy = y - y1 # 当前像素相对于搜索区域顶部的偏移
dx = x - x1 # 当前像素相对于搜索区域左侧的偏移
d = D12[dy, dx] # 当前像素的综合距离
# 如果距离更小,更新距离矩阵和标记矩阵
if D[y, x] == -1 or d < D[y, x]:
D[y, x] = d
L[y, x] = k
# 根据新的标记矩阵更新聚类中心
clusters(I, L, C)
return L, C # 返回最终的标记矩阵和聚类中心信息
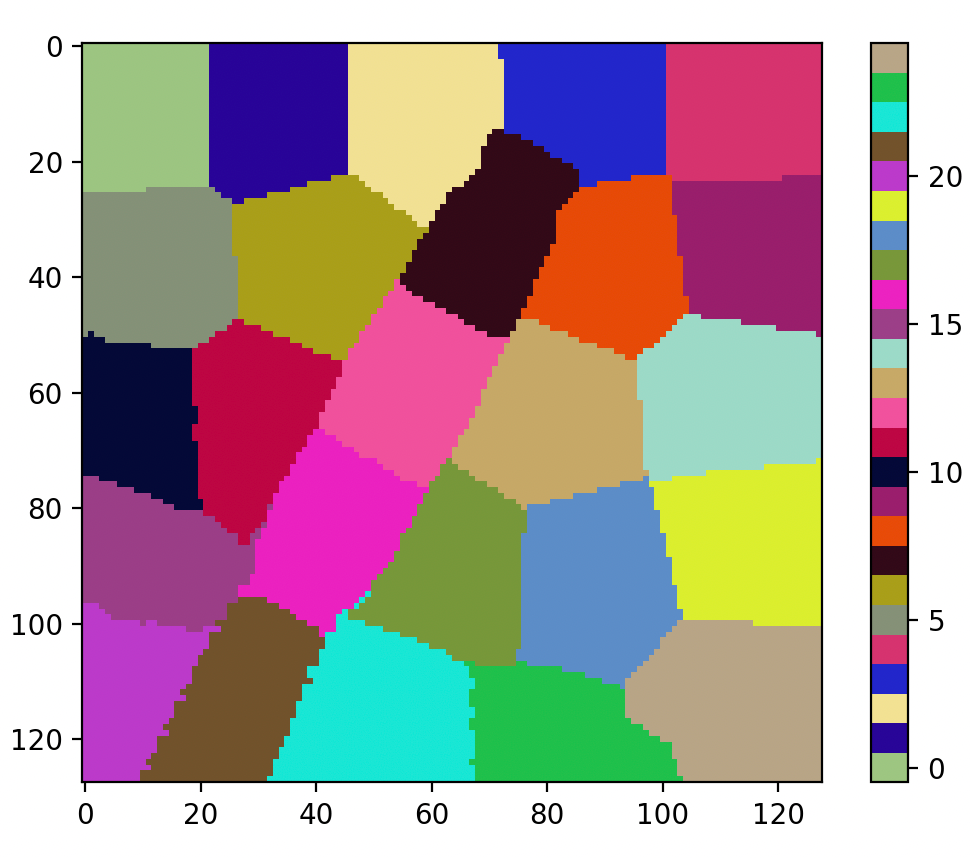
可见图像被分割成多个规则的超像素区域,每个区域用不同的颜色标记,超像素内部像素值相似,区域边界大致沿着原图像的灰度变化分布。
超像素数量和形状由输入参数控制,当前结果显示了约5 \times 5 = 25 个超像素。