
汇报
编辑分享

大家好,我的实习主题是
Bonjour à tous, mon sujet de stage est
Dans le laboratoire de signaux et systèmes, le professeur superviseur est Nabil El Korso.

我今天主要介绍四方面,第一部分是降尺度介绍,第二部分是数学理论,第三部分是结果,第四部分重点于在降尺度的背景下缺失数据的模拟
Je vais principalement présenter quatre aspects . La première partie est l'introduction de régionalisation, la deuxième partie concerne la théorie mathématique, la troisième partie concerne les résultats, et la quatrième partie se concentre sur la simulation des données manquantes dans le contexte de la réduction d'échelle.
我做了很多页ppt,但只有20页是主要的,其他ppt更多的是提供一些直观信息,但是我会快速的passer 他们
J'ai fait beaucoup de pages de slide, mais seulement 20 pages sont principales, les autres pages fournissent les informations claire, donc je vais les passer rapidement.

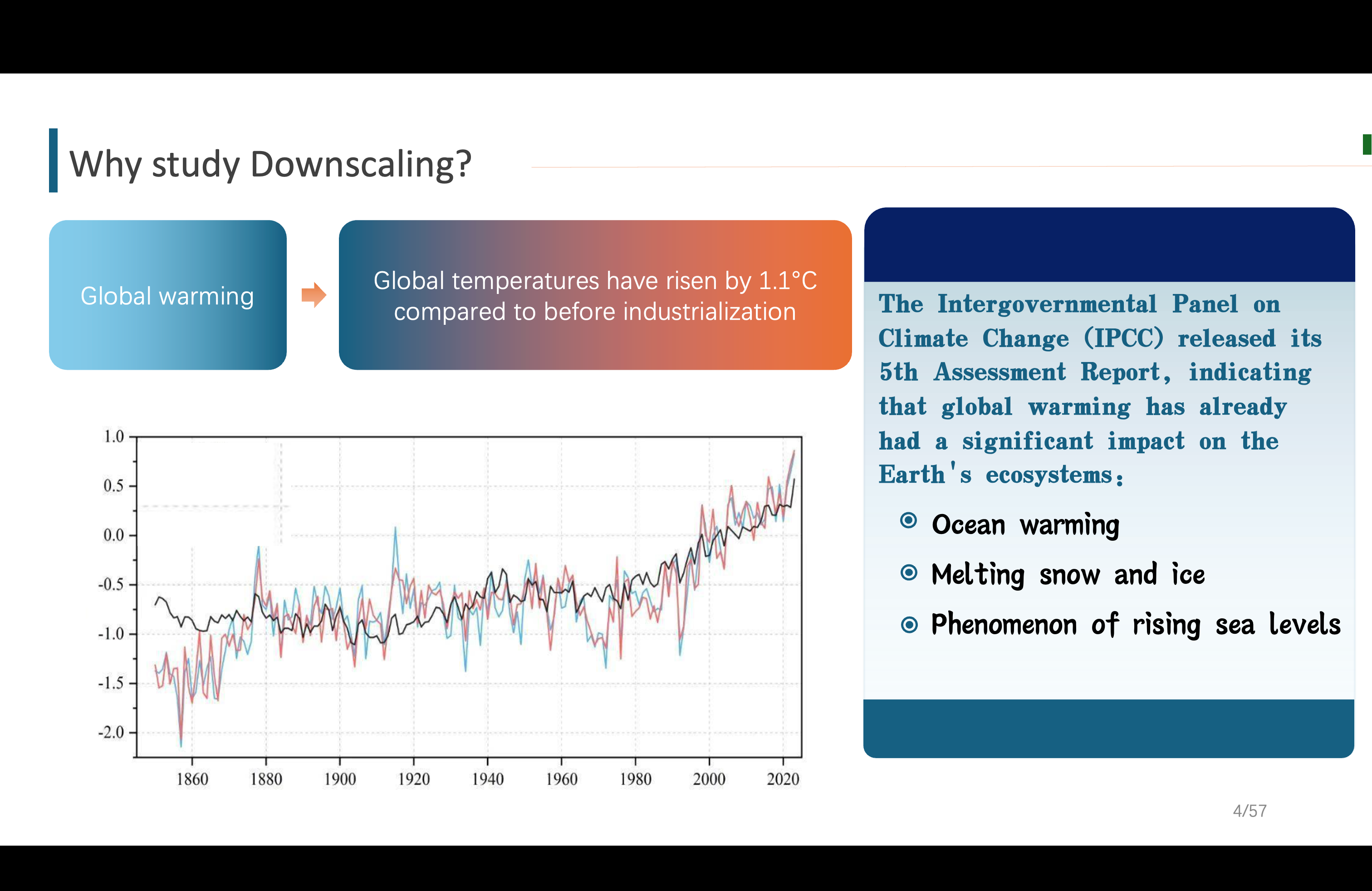

关于介绍方面,首先就是由于现在有气候恶化问题,我们需要研究、预测未来气候变化
En ce qui concerne l'introduction, tout d'abord, en raison du problème de détérioration du climat actuel, nous devons étudier et prédire les changements climatiques futurs.

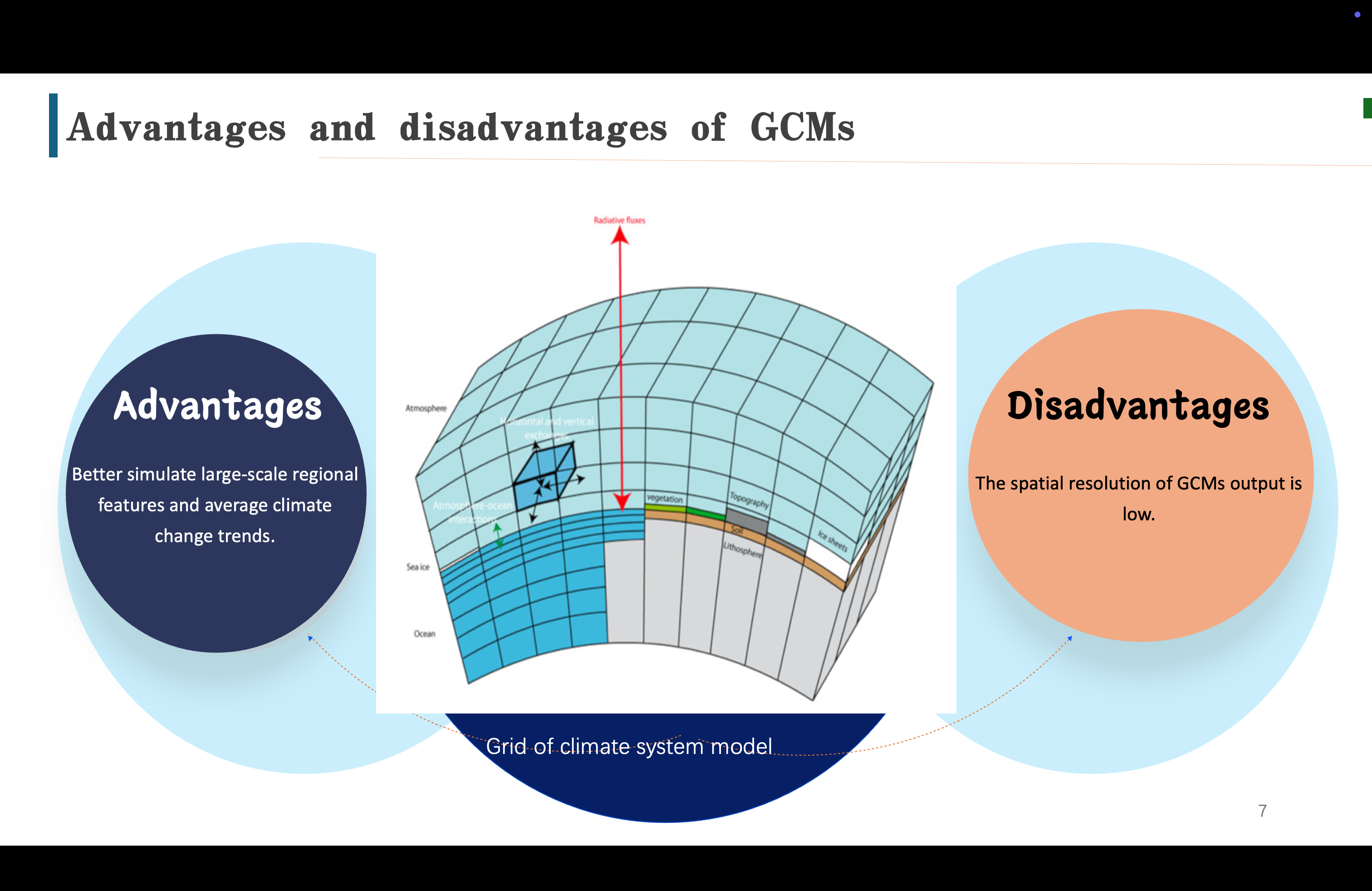
目前预测方法是通过全球气候模型 GCM,其原理是把地球划分成三维网格,在每一个网格上,都有一些大气因子,我们称之为prédicteur,携带着用于预测未来气候的关键信息,比如温度、湿度、风向,然后我们可以用这些信息来计算海洋的降水 etc
Le méthode de prédiction actuelle consiste à utiliser le modèle climatique mondial GCM, qui divise la Terre en une grille tridimensionnelle. Sur chaque grille, il y a des facteurs atmosphériques que nous appelons prédicteurs, qui transportent des informations clés pour prédire le climat futur, telles que la température, l'humidité, la direction du vent, puis nous pouvons utiliser ces informations pour calculer les précipitations océaniques, etc.
它的优点是,真的可以反应出气候变化,也就是它的预测是可靠的,但是他有一个问题,就是其输出分辨率很低。
son avantage est qu'il peut vraiment refléter les changements climatiques, c'est à dire que ses prévision sont fiables, mais il a un problème, c'est que sa résolution de sortie est tres faible
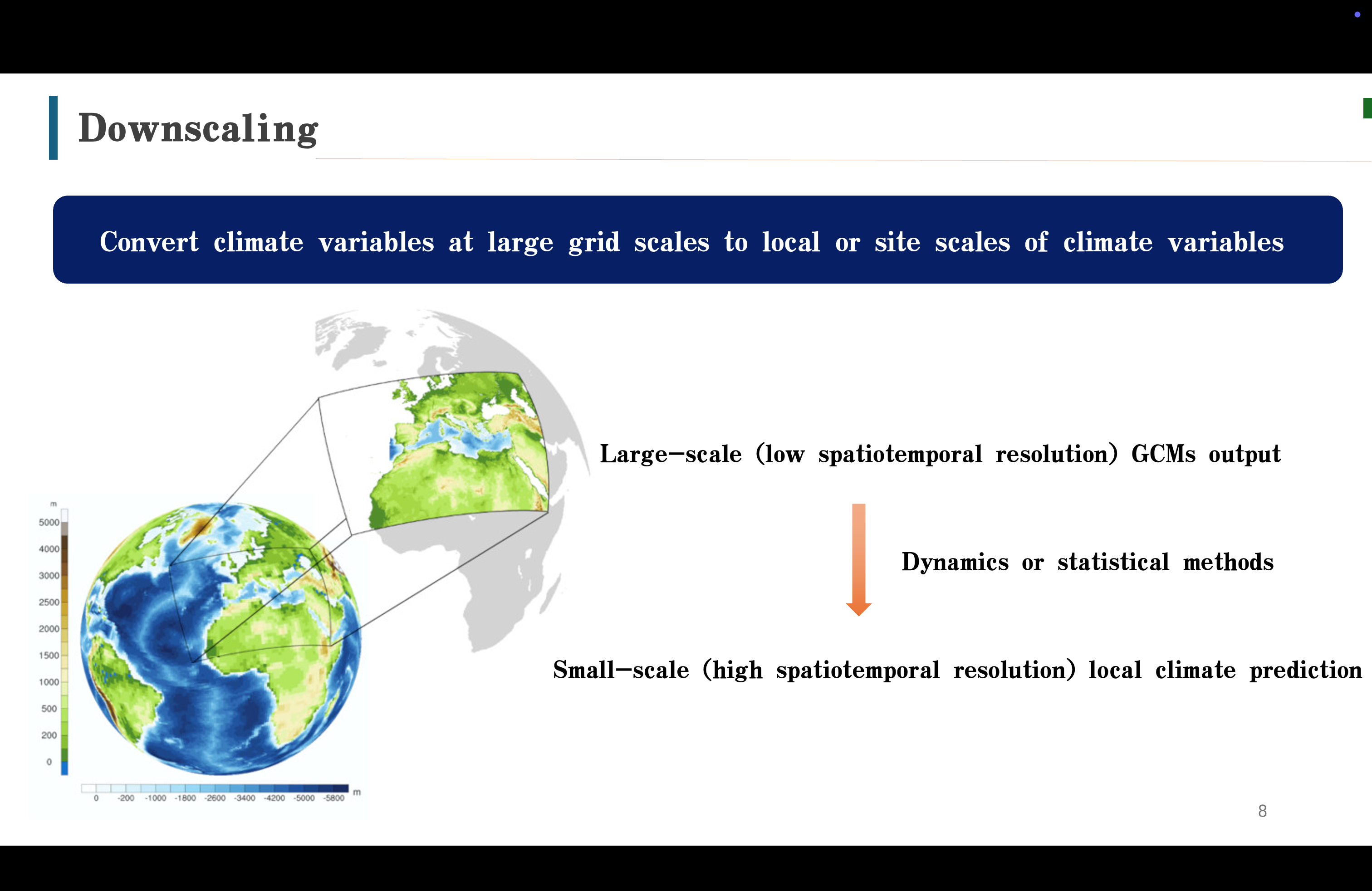
所以降尺度的任务就是,将低分辨率的GCM输出结果,通过动力或者统计降尺度方法,转换成高分辨率的局部预测。
Donc c'est l'objectif de downscaling. il consiste à convertir les résultats de sortie GCM à à basse résolution en prévisions locales à haute résolution à l'aide de méthodes de dynamic downscaling ou statistical downscaling

降尺度方法有三个分类,动力降尺度,统计降尺度,以及动力和统计相结合的降尺度方法
c'est la classification de downscaling,
动力降尺度,简单来说,就是求解物理方程,所以即使他的结果很好,很精细,但是计算量很大
La réduction d'échelle de puissance, en termes simples, consiste à résoudre des équations physiques, mais même si ses résultats sont très bons et très précis, le charge de calcul est grand
所以我们重点关注,统计降尺度 就是寻找 GCMs 的输出 和 真实观测值之间的统计关系,用历史数据训练好一个模型,然后预测未来气候。优点是,不仅精度高,计算量小
Donc le statistical downscaling consiste à trouver la relation statistique entre la sortie de GCM et les valeur d'observation, on entraine un modele avec les données historiques, et puis prédire le climat futur.
L'avantage est: la précision est élevée, la chaque de calcul est faible



第二部分 涉及到广义线性模型模型的数学理论, 这部分不是重点,因为很多数学理论来源于网络,并且解释起来非常compliqué,我会快速的passer他们
La deuxième partie concerne la théorie mathématique des modèles linéaires généralisés, qui n'est pas la partie principal, car de nombreuses théories mathématiques proviennent d'Internet et sont très compliquées à expliquer. Je vais les passer rapidement.

这是线性回归模型的基本表达式,我们对其进行了扩展,让Y可以服从不同的分布,因此这就是广义线性模型的来源c'est pourquoi on a GLM,也就是说Y可以服从指数分布族里的任何一个分布
C'est l'expression de base du modèle de régression linéaire, que nous avons étendu pour permettre à Y de suivre différentes distributions, c'est pourquoi nous avons le modèle linéaire généralisé (GLM), ce qui signifie que Y peut suivre n'importe quelle distribution dans la famille des distributions exponentielles.

他有三部分, 最关键的部分是连接函数, 把期望输出和线性预测器连接起来,在我们的GLM降水区域化中,我们的x 就是大气因子,prédicteur,我们的y 就是观测数据,所谓的建立统计关系,就是找到这个beta ,那么问题来了,我们应该怎么去估计这个beta呢?那肯定用最大似然估计
il y a trois parties, la partie la plus importante est link fonction, qui relie l'expérience au prédicteur linéaire.. Dans notre régionalisation des précipitations GLM, notre x est le facteur atmosphérique, le prédicteur, et notre y sont les données observées. L'établissement de la relation statistique consiste à trouver ce beta. Alors, la question est, comment devrions-nous estimer ce beta ? Cela doit certainement être fait par la méthode de maximum de vraisemblance.
notre objectif est trouver beta, alors comment faire pour estimer ce beta? ==> par l'estimation de maximum de vraisemblance.

由于最大似然估计部分在代码中可以直接使用对应的函数来实现,所以我也跳过这里
Étant donné que la partie de l'estimation du maximum de vraisemblance peut être directement mise en œuvre dans le code à l'aide de la fonction correspondante, je vais passer ici.

我们将重点解释GLM模型在统计降水降尺度中的表现
Nous allons nous concentrer sur la performance du modèle GLM dans la réduction statistique des précipitations.
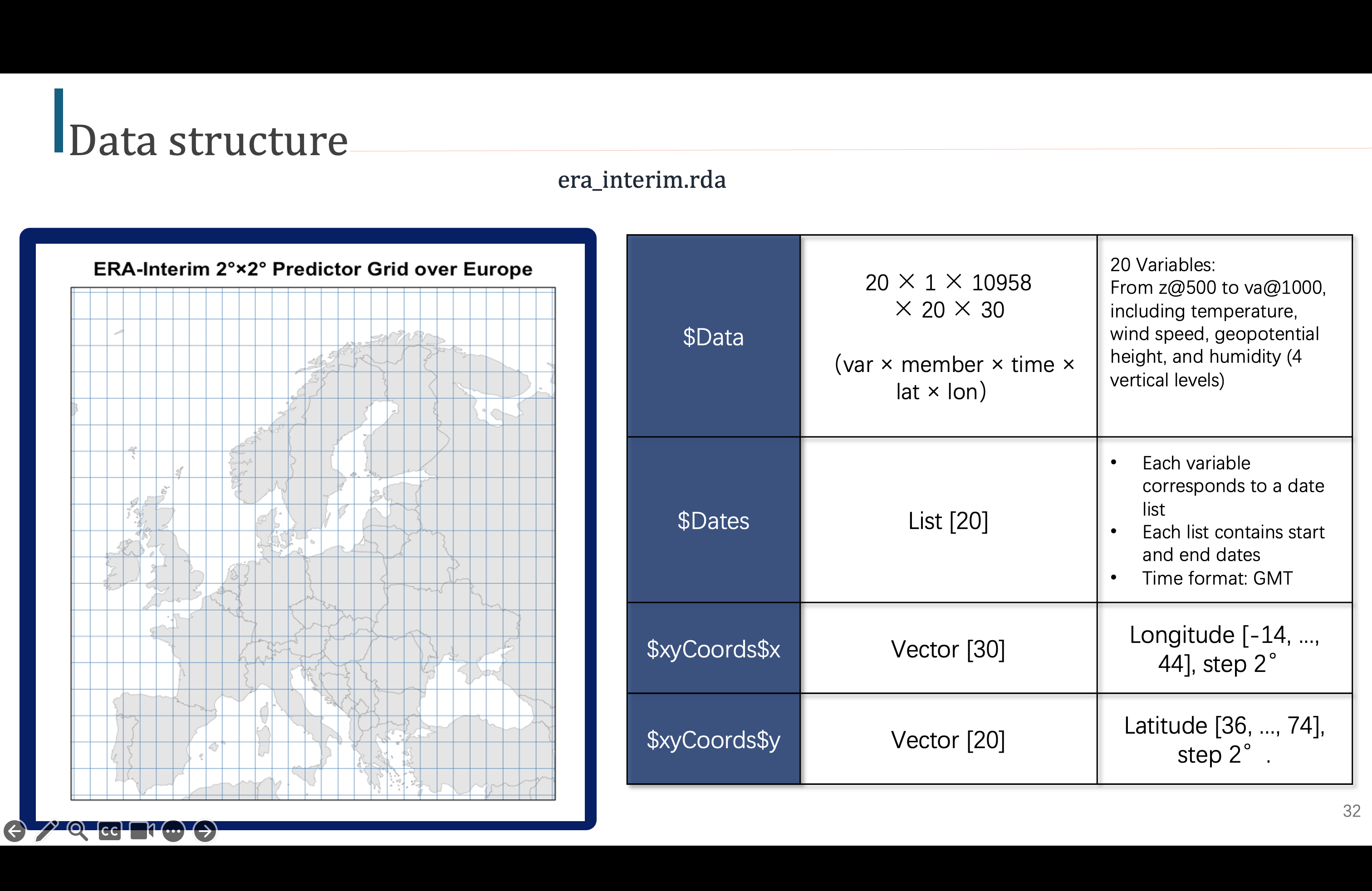
首先我们先看一下我们有的数据,这个是预测因子,也就是x,把欧洲区域划分成三维网格,经度、纬度,以及不同大气压层,在每个网格里,我们有20个predicteur,温度,风速,湿度,垂直高度,然后在四个垂直大气层上,也就是fois 4,然后我们一共有10958天的数据,因此会组成这么一个矩阵,维度很大,
Tout d'abord, regardons les données que nous avons. Ce sont des facteurs de prédiction, c'est-à-dire x, qui divisent la région européenne en une grille tridimensionnelle, longitude, latitude, et différentes couches de pression atmosphérique. Dans chaque grille, nous avons 20 prédicteurs : température, vitesse du vent, humidité, hauteur verticale, puis sur quatre couches atmosphériques verticales, soit 4 fois. Nous avons un total de 10 958 jours de données, ce qui formera une matrice de dimensions très grandes.

这个数据是predictand,也就是86个站点的观测数据,然后同样有10958天
Ces données sont des predictands, c'est-à-dire les données d'observation de 86 sites, avec un total de 10958 jours.

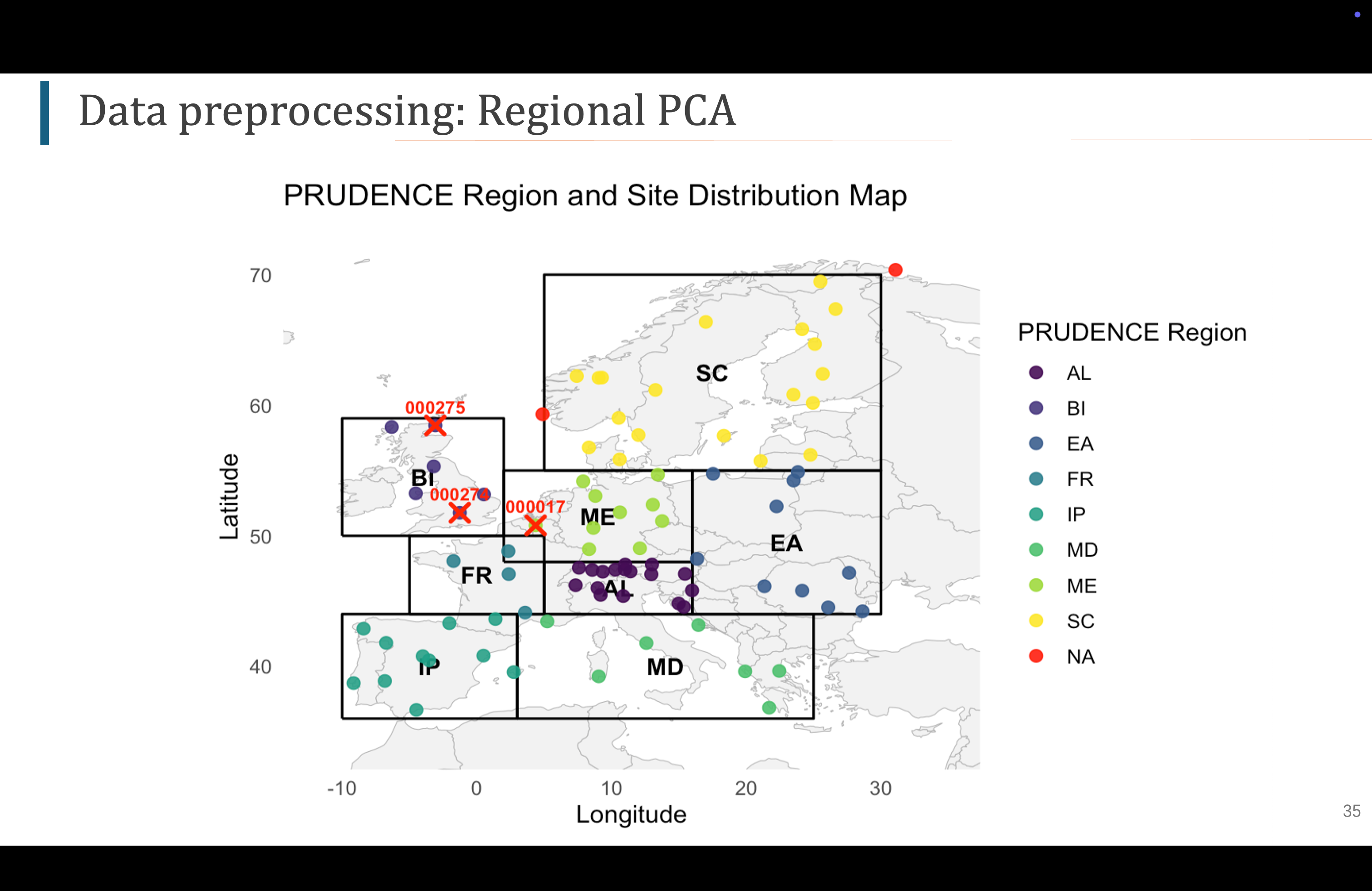
由于我们之前看到x prédicteur 的数据维度很大,所以必须进行降维操作,我们使用pca,提取能够解释95方差的那些主成分pcs,我们是根据prudence区域来进行PCA的。也就是说,我们要对每个站点都训练一个GLM 模型,那么什么作为GLM模型的输入呢,每个区域的主成分,这样的好处是,我们考虑了地理因素,比如说法国站点,我只用法国的prédicteur信息降维度后的主成分来进行训练,而不再使用德国的大气信息来训练,所以提取的主成分能更好解释该区域的大气变化。
Étant donné que nous avons vu que les dimensions des prédicteurs x étaient très grandes, nous devons effectuer une opération de réduction de dimension en utilisant l'ACP pour extraire les composantes principales (pcs) qui expliquent 95% de la variance. Nous effectuons l'ACP en fonction de la région de prédiction. En d'autres termes, nous devons entraîner un modèle GLM pour chaque site, en utilisant les composantes principales de chaque région comme entrée du modèle GLM. L'avantage est que nous prenons en compte les facteurs géographiques. Par exemple, pour les sites en France, j'utilise uniquement les composantes principales des prédicteurs de la France pour l'entraînement, au lieu d'utiliser les informations atmosphériques de l'Allemagne. Ainsi, les composantes principales extraites peuvent mieux expliquer les variations atmosphériques de cette région.
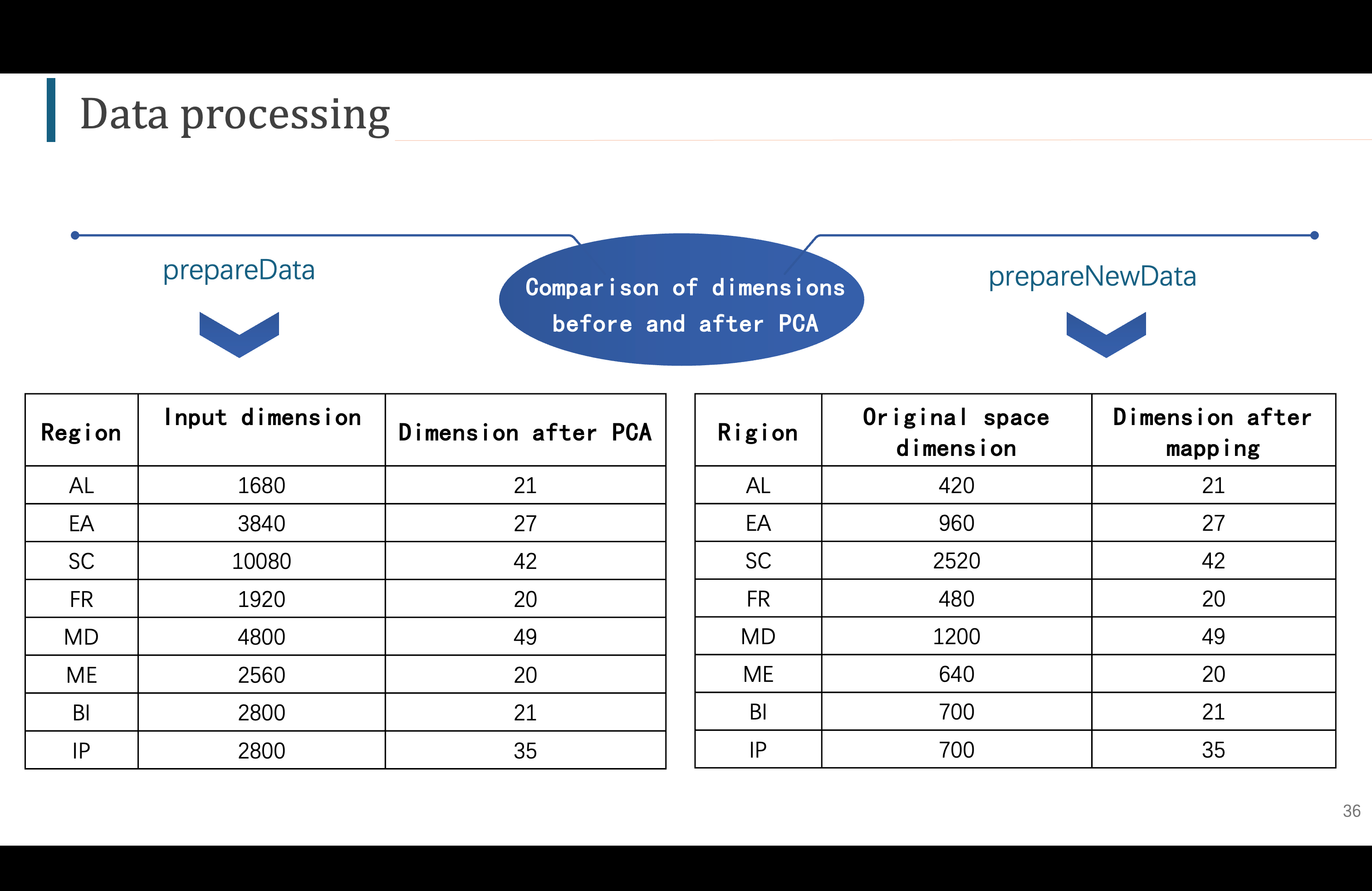
这是经过PCA后的数据维度,大大减少了训练的计算量
C'est la dimension des données après PCA, ce qui réduit considérablement la quantité de calculs d'entraînement.

然后由于我们只有一份数据,理论上应该有一份历史数据用于训练,一份未来数据用于验证GLM模型预测的准确性,但是我只有一份历史数据,所以我把历史数据使用交叉验证,分成5份,4折用于训练,1折用于验证预测效果
Ensuite, comme nous n'avons qu'un seul ensemble de données, en théorie, il devrait y avoir un ensemble de données historiques pour l'entraînement et un ensemble de données futures pour valider l'exactitude de la prédiction du modèle GLM. Cependant, je n'ai qu'un seul ensemble de données historiques, donc j'ai utilisé la validation croisée sur les données historiques, en les divisant en 5 parties, 4 parties pour l'entraînement et 1 partie pour valider l'efficacité de la prédiction.

这是降水模型的概率密度函数,由以前研究者们提出来的 ,分为两部分,这部分是伯努利分布,用于描绘降水发生与否,降水量小于1mm则是干天,如果降水量大于1mm,则被认定为雨天,那么这部分就是gamma分布,我们的最终目的就是得到这两个分布,那么伯努利分布最关键的就是这个概率p,伽马分布最关键的就是形状和速率参数。
Ceci est la fonction de densité de probabilité du modèle de précipitations, proposée par des chercheurs précédents, divisée en deux parties. Cette partie est une distribution de Bernoulli, utilisée pour décrire si la pluie se produit ou non. Si la quantité de pluie est inférieure à 1 mm, il fait sec. Si la quantité de pluie est supérieure à 1 mm, il est considéré comme un jour de pluie, ce qui correspond à une distribution gamma. Notre objectif final est d'obtenir ces deux distributions. Ainsi, la probabilité p est la clé de la distribution de Bernoulli, et les paramètres de forme et de taux sont les plus importants pour la distribution gamma.

这是我们后续使用的评判指标,AUC衡量模型区分干日和湿日的能力,COR衡量预测序列和观测序列之间的相关性,R01衡量降水频率,SDII衡量降水强度,P98衡量极端降水,这三个指标,我们后续会采用相对偏差的形式,也就是预测值和实际值做对比,查看一下偏差多少
Ceci sont les indicateurs de jugement que nous utiliserons par la suite. L'AUC mesure la capacité du modèle à distinguer les jours secs des jours humides, le COR mesure la corrélation entre la séquence de prévision et la séquence d'observation, le R01 mesure la fréquence des précipitations, le SDII mesure l'intensité des précipitations, le P98 mesure les précipitations extrêmes. Pour ces trois indicateurs, nous utiliserons par la suite la forme de l'écart relatif, c'est-à-dire comparer les valeurs prévues aux valeurs réelles pour voir quel est l'écart.
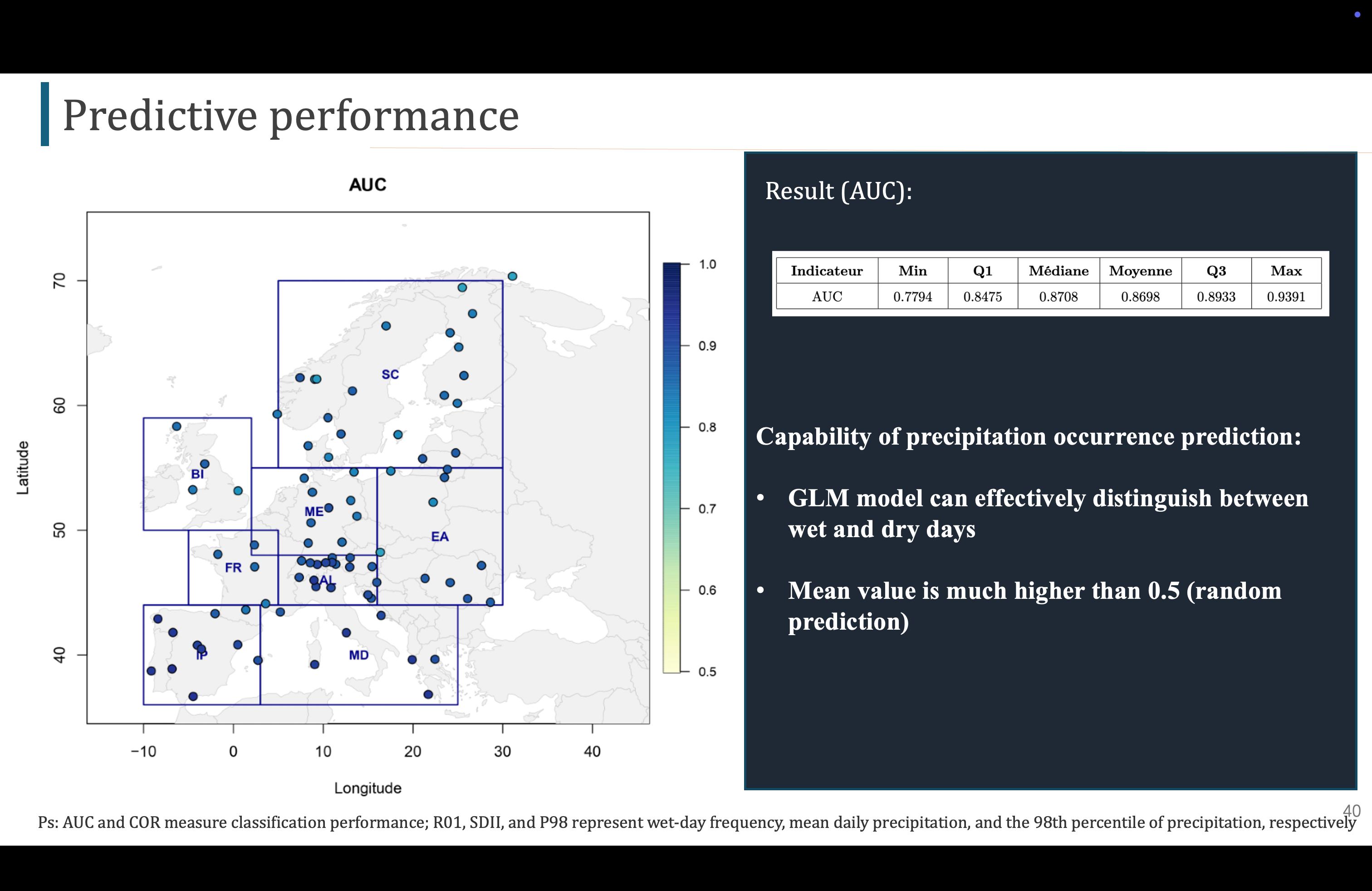
这就是我们的实验结果
对于AUC,值越大说明GLM模型区分干日湿日的能力就越强,可以出83个站点训练出的83个GLM模型的AUC平均值为0.87,说明模型可以很好的区分干日、湿日
Pour l'AUC, plus la valeur est grande, plus le modèle GLM est capable de distinguer les jours secs des jours humides. La valeur moyenne de l'AUC des 83 modèles GLM formés à partir de 83 sites est de 0,87, ce qui signifie que le modèle peut bien distinguer les jours secs des jours humides.
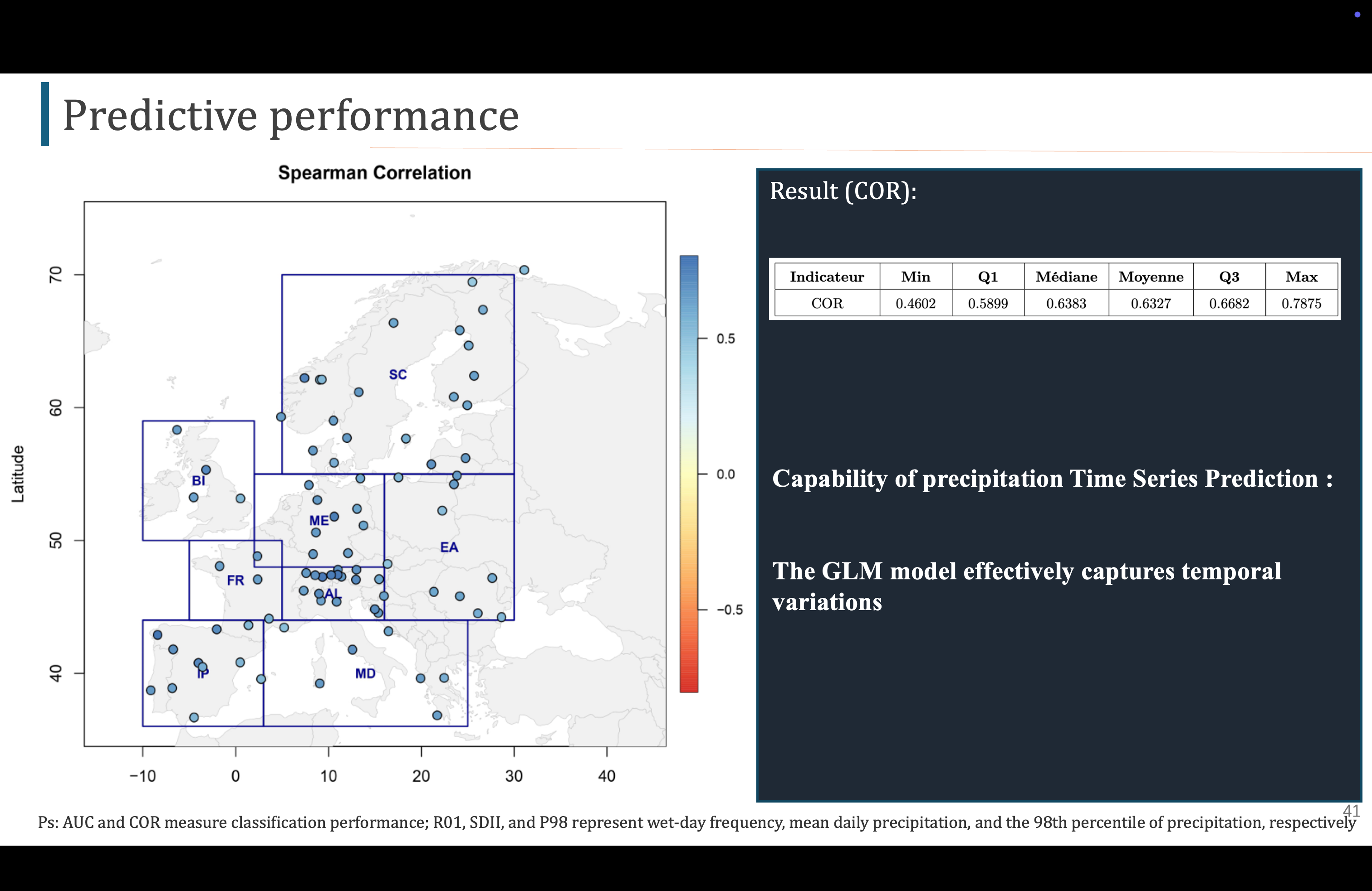
对于COR,我们发现,预测值和观测值有一定的相关性,说明得到的时间预测序列还不错
Pour COR, nous avons constaté qu'il existe une certaine corrélation entre les valeurs prédites et observées, ce qui indique que la série temporelle prédite est assez bonne.
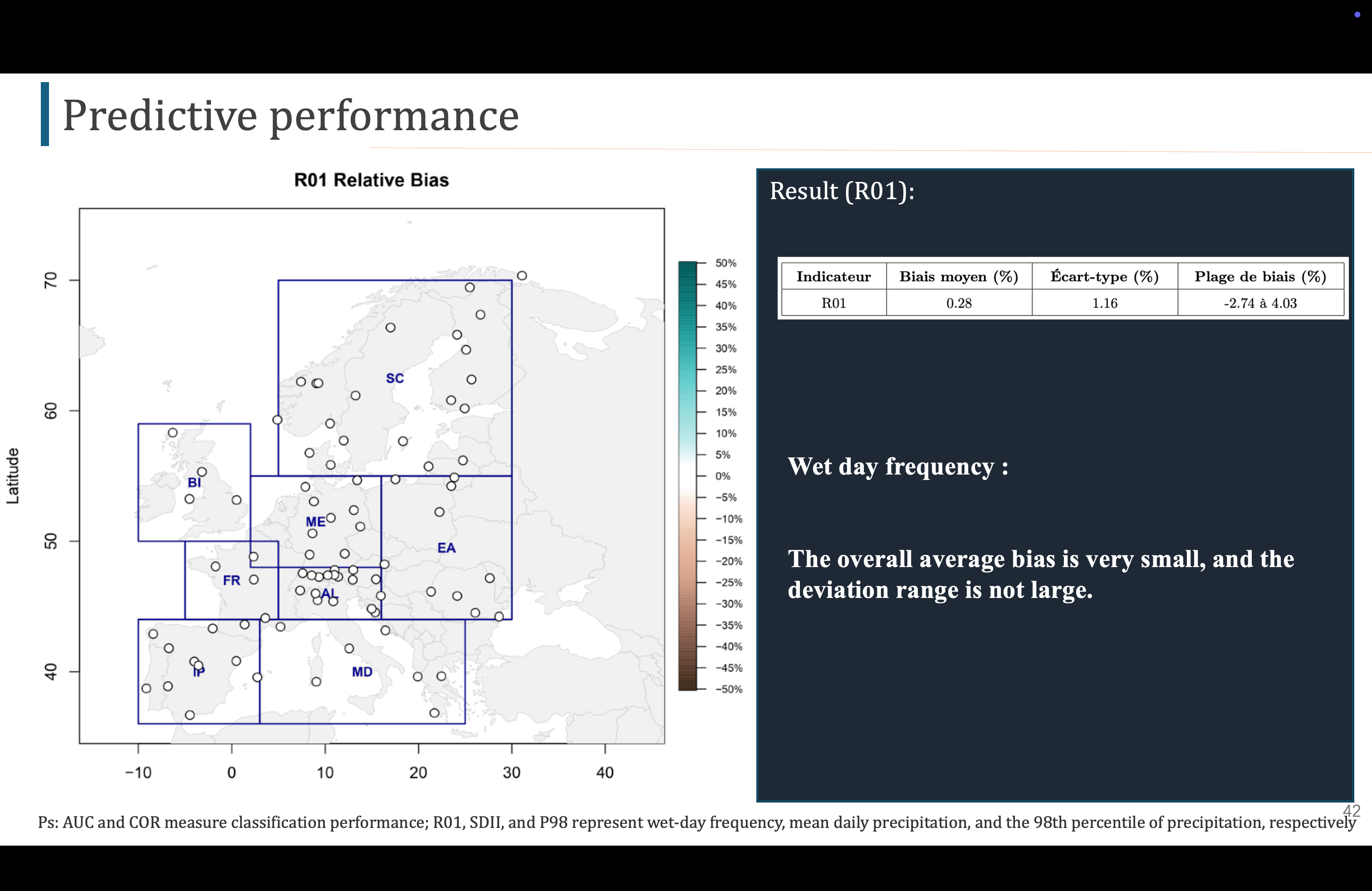
对于R01,所有站点的相对偏差都非常小,平均偏差为0.28%,方差也很小,偏差范围也不大,说明模型可以很好的预测降水频率
Pour R01, l'écart relatif de tous les sites est très faible, avec une moyenne de 0,28% et une variance également très faible. L'écart n'est pas non plus très important, ce qui indique que le modèle peut bien prédire la fréquence des précipitations.
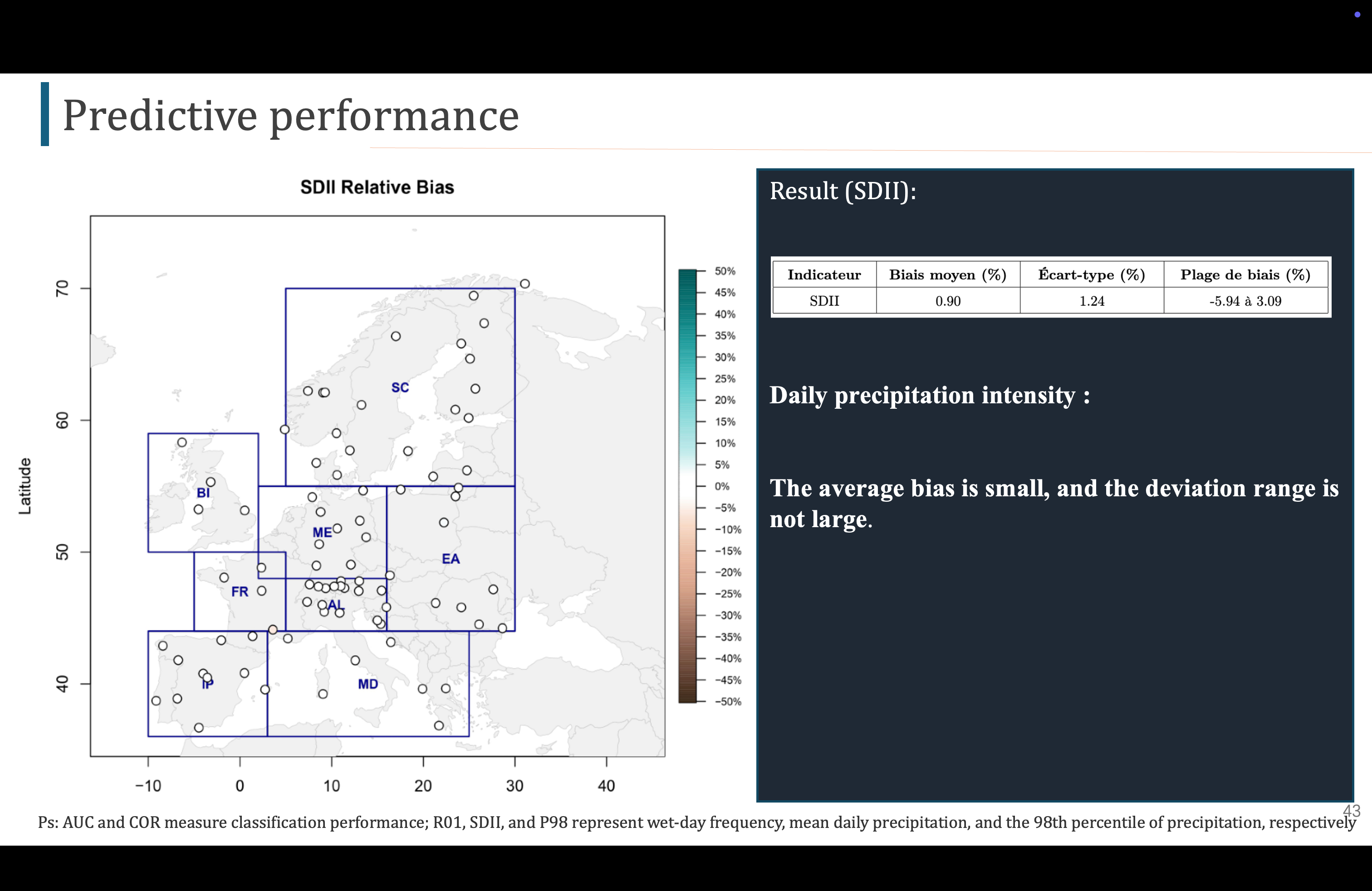
对于SDII,也一样,偏差都很小,说明模型可以很好的预测降水强度
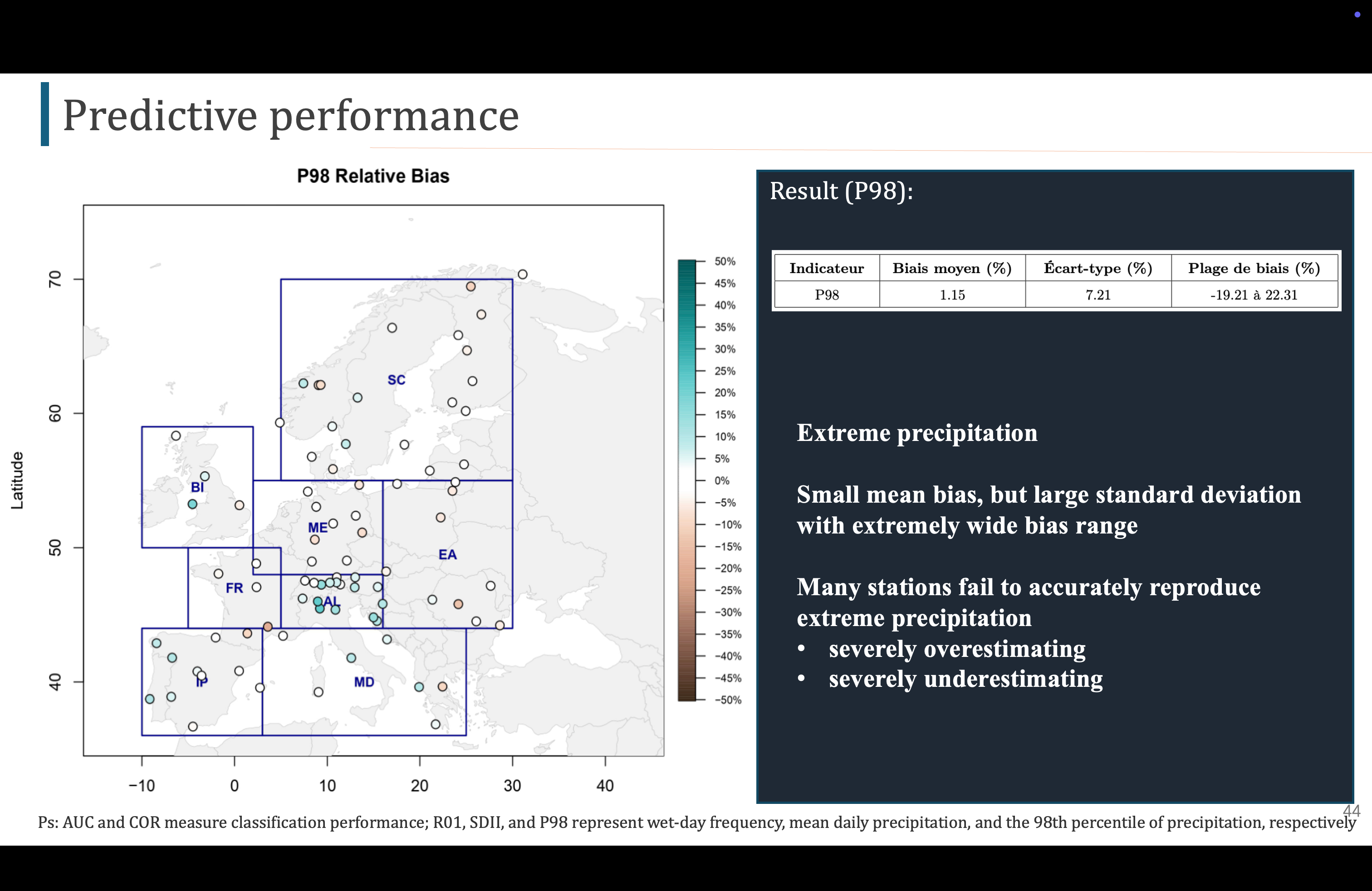
对于P98,我们可以看到某些站点有较大的偏差,要么过度高估极端降水,要么过度低估,所以GLM模型在预测极端降水方面的能力并不理想
Pour P98, nous pouvons voir que certains sites présentent des écarts importants, soit en surestimant fortement les précipitations extrêmes, soit en les sous-estimant fortement, donc la capacité du modèle GLM à prédire les précipitations extrêmes n'est pas idéale.
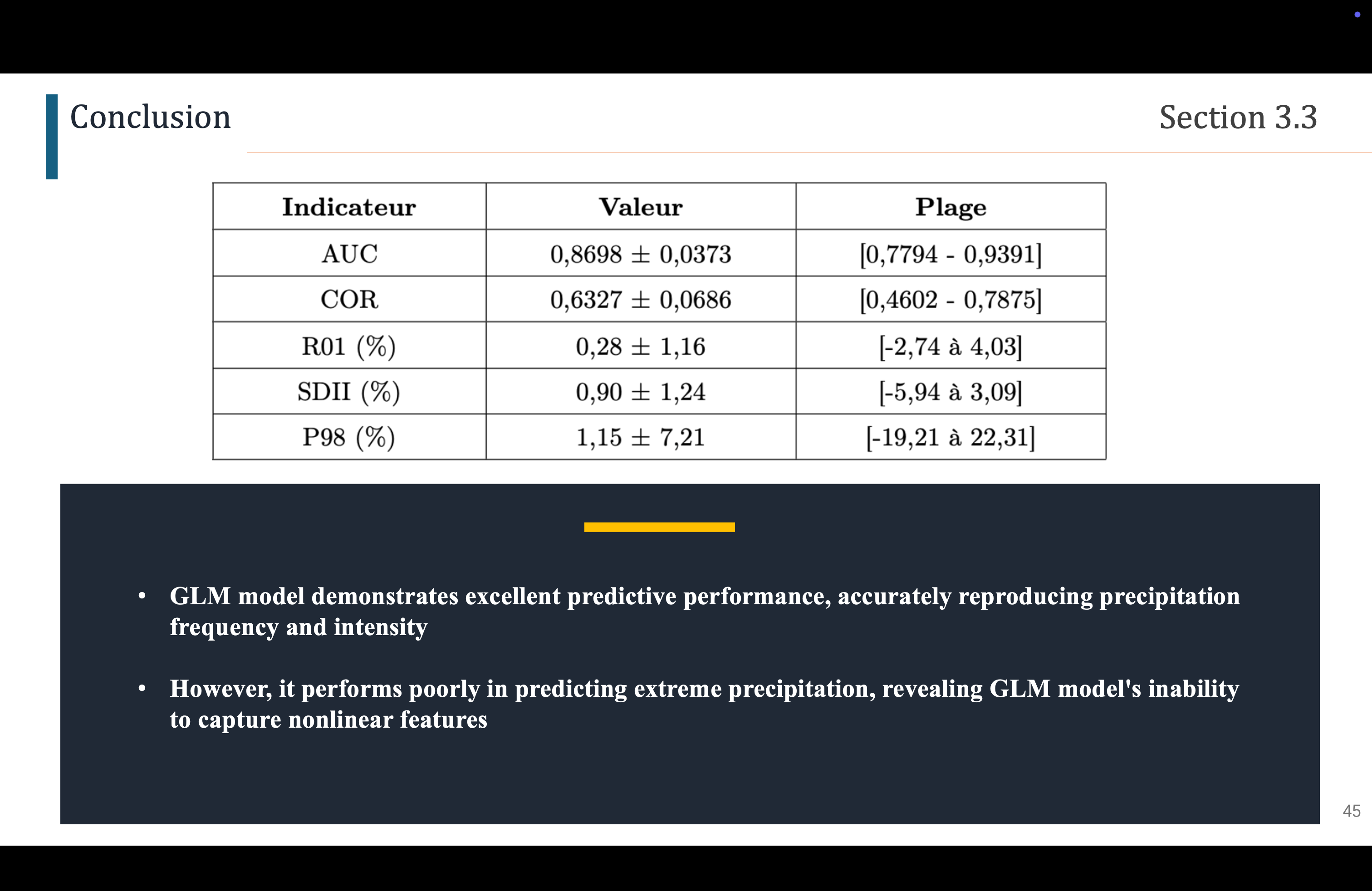
这是对刚刚结果的总结,就是我们之前说的结论
Ceci est un résumé des résultats récents, c'est la conclusion dont nous avons parlé précédemment.

第四部分是模拟缺失数据,因为很多区域化的研究都假设数据是完整无缺的,但是实际并非如此,包括我们之前的86的站点中,有三个站点带有缺失数据,因此我们删除了这三个站点,不再用于训练,所以我们模拟了这种缺失数据的情况,有两个cas,第一个是观测数据缺失,比如站点传感器实效,第二个是预测因子缺失,比如说我们缺少了一些大气信息
La quatrième partie consiste à simuler des données manquantes, car de nombreuses études régionales supposent que les données sont complètes et sans lacunes, ce qui n'est pas le cas en réalité. Parmi nos 86 sites précédents, trois sites présentaient des données manquantes. Nous avons donc supprimé ces trois sites et ne les avons plus utilisés pour l'entraînement. Nous avons donc simulé cette situation de données manquantes, avec deux scénarios. Le premier concerne les données d'observation manquantes, par exemple, une défaillance des capteurs du site. Le deuxième concerne les facteurs de prédiction manquants, par exemple, le manque d'informations atmosphériques.

然后我们采用了三种处理缺失数据的方法, complet case会删除这一天的所有其他数据,mean 会用这一天其他的数据的平均值来填补缺失值,neighbor会用最近几个站点,或者最近几个网格的这一天数据的平均值来填补
Ensuite, nous avons utilisé trois méthodes pour traiter les données manquantes. "complet case" supprimera toutes les autres données de ce jour-là, "mean" utilisera la moyenne des autres données de ce jour-là pour remplir les valeurs manquantes, "neighbor" utilisera la moyenne des données de ce jour-là des stations les plus proches ou des grilles les plus proches pour remplir les valeurs manquantes.
最后我们对于y 的缺失数据模拟结果如下,在1%缺失率下,所有性能指标表现变差,AUC COR降低,偏差变大,方差偏大,但是三种方法中,neigh方法的表现最好,随着缺失率的上升,GLM模型的预测性能越来越差,偏差不断变大,但是一直都是neigh方法最好,当10%缺失率的时候,CC方法会删除几乎所有的数据,我们就没有数据用于训练了,所以这里是空的,对于mean neigh方法,neigh方法最好
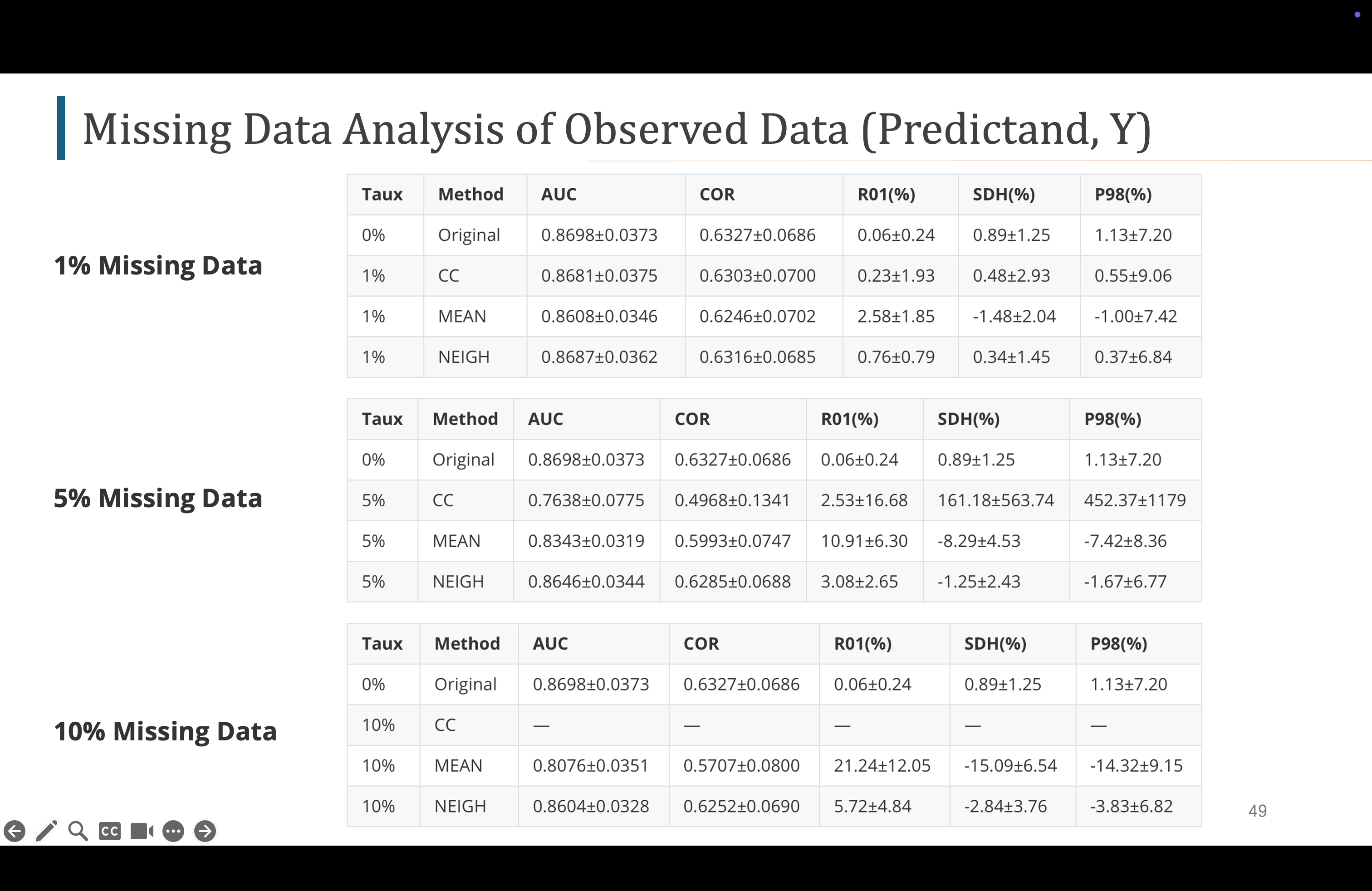
Voici les résultats de la simulation des données manquantes pour y. Avec un taux de manque de 1 %, toutes les mesures de performance se détériorent, l'AUC COR diminue, le biais augmente, la variance est élevée, mais parmi les trois méthodes, la méthode neigh est la meilleure. Avec l'augmentation du taux de manque, les performances prédictives du modèle GLM deviennent de plus en plus mauvaises, le biais augmente continuellement, mais la méthode neigh reste la meilleure. Lorsque le taux de manque est de 10 %, la méthode CC supprime presque toutes les données, nous n'avons donc plus de données pour l'entraînement, donc cette partie est vide. Pour la méthode mean neigh, la méthode neigh est la meilleure.

这里是对x进行缺失数据模拟,由于x的维度太大,20prédicteurs fois 10958 fois log fois lat,所以即使1%的缺失数据也会删除所有的天数,因此我减少了缺失率,但是这样就没办法比较了,但是我们依旧可以看出变化趋势,随着缺失率的上升,偏差开始变大
Voici une simulation de données manquantes pour x. En raison de la grande dimension de x, 20 prédicteurs fois 10958 fois log fois lat, même une perte de données de 1% entraînerait la suppression de tous les jours. J'ai donc réduit le taux de perte, mais cela rend la comparaison impossible. Cependant, nous pouvons toujours observer une tendance de changement, avec une augmentation du taux de perte, les écarts commencent à augmenter.
对于mean 和neigh方法,最开始的时候没有太大的差别,但是在10%缺失率下,我们可以看到neigh方法的偏差更小,方法更好
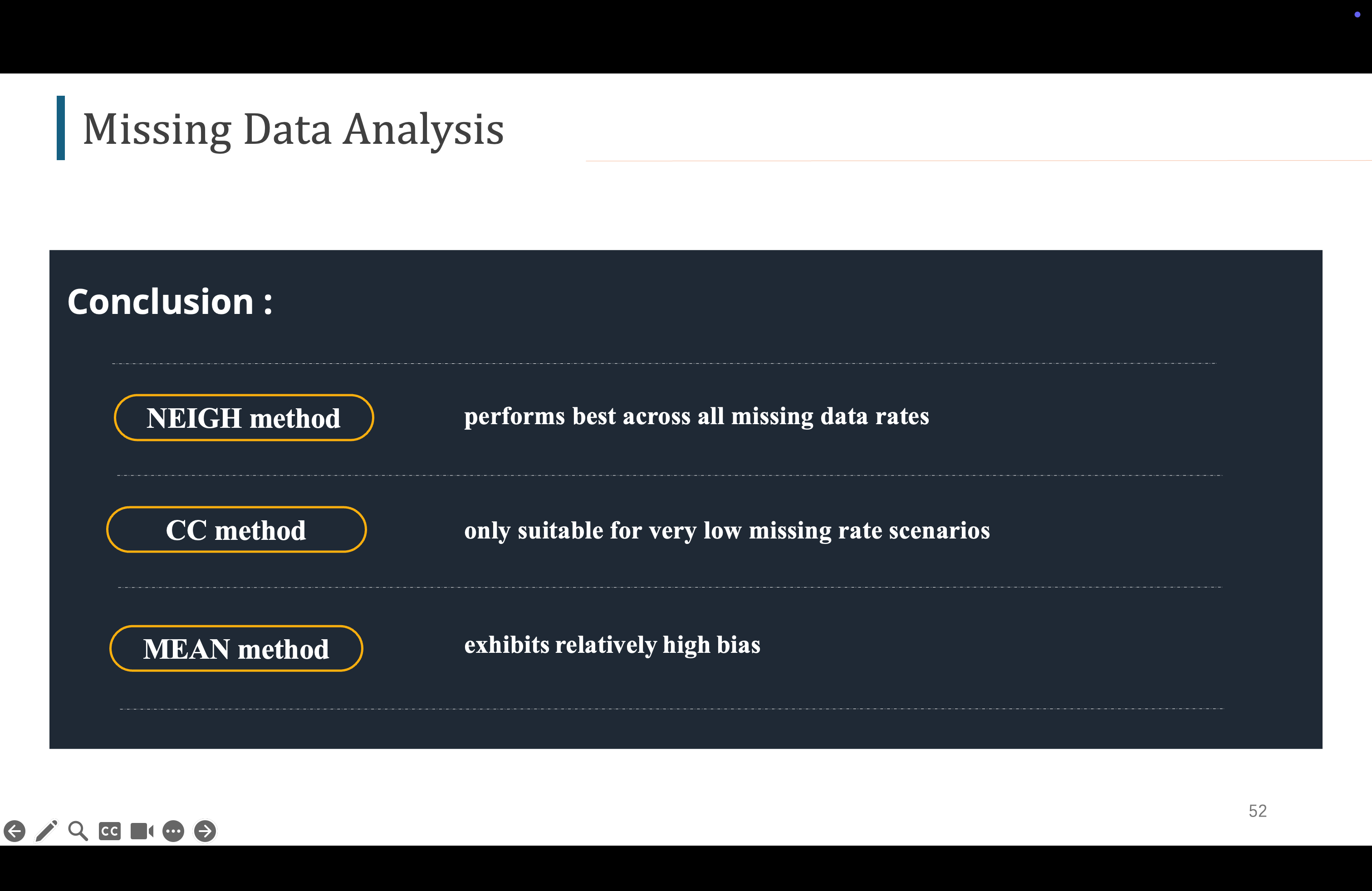
总的来说,neigh方法是最好的,cc方法只适用于极小缺失率,因为会删除太多天数,mean方法虽然用平均值插补,但是没有考虑临近信息,插补值并不好。

这就是我实习期间做的所有工作,一方面先评估了GLM模型在降水区域化中的应用,另一方面模拟缺失数据的情况,查看当降水区域化中存在缺失数据的时候,三种不同的处理方法的比较,以及对GLM模型预测性能的影响。
这是指数分布族的概率密度函数, 我们之前要求的参数bêta 被包含在 thêta里, 这是具体的参数关系, 所以后面参数估计的时候我们直接求 theta 即可, 一样的
c'est la fonction de densité de probabilité de la famille de distribution exponentielles. le beta que on veux obtenir est inclus dans theta, c'est la relation spécifique des paramètres, donc dans la suite on peux directement calculer theta, ca suffit.
那么怎么找到这个参数呢, 换句话说, 如何在训练过程中找到最优参数 bêta呢? 我们假设现在有这么一组数据, 他们是独立同分布的, x是 预测因子 y是 predictand 观测数据,
alors, comment trouver ce paramètre, autrement dire comment trouver le meilleur beta?
on suppose que nous avons un ensemble de données, qui sont indépendantes et identiquement distribuées, x est predictors y est predictand c'est à dire les données d'observation
那么其最大似然估计就可以表示成这个形式,然后取对数, 最后求令它最大的那个参数值, 这就是大体的流程
alors son likelihood function peut être présenté sous cette forme, puis on prend log, enfin on cherche la valeur du paramètre qui maximise log likelihood function, c'est le processus général.
这部分是推导过程, 非常详细,但是我在这里不过多介绍了,因为参数估计不是我们的重点, 并且在R里已经被写在函数里了, 最关键的是, 这不是数学课, 所以我只说两点重要的
c'est la dérivation , très détaillé, je vous présente pas tous, car l'estimation de paramètre n'est pas notre point clé, il est écrite déjà dans la fonction de R.
je ne présente que deux points le plus importants.
第一, 这是对 对数似然估计求一阶偏导后的表达式,令他等于0
premièrement, c'est l'expression de la dérivée partielle de premier ordre, le faire égal à 0
也就是这里, 由于方程没有解析解, 所以用数值优化方法求解,梯度下降法,牛顿法, 以及牛顿法的变种. 我们可以看到所有方法的最后公式, 和优缺点
c'est ici, mais en raison de l'absence de solution analytique de l'équation, on utilise les méthodes d'optimisation numérique: décent de gradient, la méthode de newton, ainsi que la variante de la méthode de newton: s'appelle IRLs
nous pouvons voir les formules de toutes les méthodes, leur avantages et inconvénient.
对于牛顿法, 才用了近似的方法, 用海森矩阵来代替学习率参数,然后另一方面,由于海森矩阵这个值计算量太大,所以为了简化,通常用它的期望值来代替海森矩阵, 计算更方便, 本质上是去除掉了这部分
pour la thémode de newton, il a utilisé la matrice de hessienne pour remplacer le paramètre du taux d'apprentissage, mais le calcul de la matrice de hessienne est trop coûteux, pour simplifier, on utilise son expérience pour la remplacer.
ici il y a trois prouves. qui a bien expliqué pourquoi on fait comme ça
IRLS本质上仍然是牛顿法, 只是做了一些改进, 每次迭代重新计算权重
IRLS est essentiellement la méthode de Newton, mais avec quelques améliorations, il recalcule les poids à chaque itération.
这是他最后表达式和优点,他和牛顿法最后结果是一样的
c'est son expression final et avantage, et le résultat final est le même que la méthode de Newton.
这部分是针对论文里的伯努利 伽马分布进行参数估计, 换句话说, 这就是一个具体例子, 当Y服从伯努利分布或者伽马的时候, 看一下最大似然估计 来估计参数的流程和结果
c'est un exemple concret, dans le papier, ils ont utilisé ce genre de distribution mixée. c'est la partie de Bernoulli et c'est la partie de gamma
本质上就是举了两个具体例子,这个流程符合我们之前解释的流程
avec les densité de probabilité de chaque distribution, on calcul déraillement concrètement le processus qu'on a présenté .
c'est le résultat de log likelihood
Gamma分布也一样,这是最后最大似然估计表达式
c'est pour la distribution de gamme, pareil , on a eu l'expression de log likelihood
然后进行参数估计,三种方法
et puis on fait l'estimation de paramètre , avec trois méthodes de l'optimisation numérique
下面是第三部分,介绍论文,以及我我复现的结果
Voici la troisième partie, je présente le papier et les résultats que j'ai reproduits.
他关注的重点是可迁移性,就是,我们用历史数据训练好的统计模型,是否真的可以用于未来气候预测?预测结果是否真的可靠
son point focalisé est la tansférabilité, c'est à dire, le modele statistique que nous avons entraînés avec des données historiques peuvent-ils vraiment être utilisés pour prédire le climat futur?
les résultats des prévisions sont- ils vraiment fiable?
这是论文中用到的数据,再分析数据就是predictors, 温度等等,一共20个, 观测数据就是predictand
c'est les données utilisé dans le papier, les donnée réanalysé est x, signifie le predictors, au total 20, température etc
les données d'observation est y, predictand, il a présenté daily precipitation at 83 station
这是论文中使用的降水建模,这部分是伯努利部分, 这部分是伽马部分, 然后我们希望得到这三个参数,来正确的描述这个混合分布
c'est la modélisation des précipitaion utilisé dans le papier, on l'ai déjà présenté
ce que on veut obtenir, c'est ces trois paramètres, pour décrire correctement cette distribution mixé.
论文中对比了三种方法, Glm cnn 和后验随机网络,这是他们详细的描述
dans le papier il a comparé trois méthodes, GLM CNN APRF, c'est ses descriptions détaillées.
对于 CNN Glm都需要进行标准化, 然后GLM和 APRF是为每个站点都构建一个模型, 所以总共有83个模型, CNN只构建一个模型
pour CNN GLM on a besoins de faire la normalisation, c'est le formule de normalisation
et GLM et APRF construisent un modèle pour chaque station site, donc un total de 83 modèles
cnn ne construit qu'un seul modèle
这部分是论文中用到的诊断指标,以及他们对应的含义, AUC代表模型能很好的区分干天和湿天, COR
c'est les indicateur utilisé dans le papier, ainsi que leur signification correspondante.
AUC est la capacité de distinguer les jours secs des jours humides.
R01是湿润天的频率
R01 est la fréquence des jours humides
SDII是降水强度
SDII est l'intensité des précipitations
P98反应极端降水分布情况
P98 réagit à la distribution des précipitaion extreme.
DD DW是从干天转湿天的可能性,也就是对未来降水预测的概率
DW est la probabilité de passer d'une période sèche à une période humide, c'est a dire la probabilité des prévision de précipitations futures
首先我们看3.1节交叉验证的结果, 这是理想条件, 只使用再分析数据, 我们可以看到所有方法在 AUC COR上结果都差不多
Tout d'abord on voit le résultat de section 3.1, la condition idéal avec la validation croisée, c'est à dire, on n'utilise que les données réanalysé, on peux voir que les résultats de tous ces 3 méthodes sont similaires
在分布指标上, R01基本相同, SDII中CNN更好一些, P98中 APRF更好
pour l'indicateur de distribution, R01 est pareil,le biais est presque 0% ,pour SDII, CNN est un peu mieux, pour P98 APRF est un peu mieux
这是非理想条件下的对比, 也就是使用GCM的输出来进行预测, 我们可以看到 所有结果对比于理想情况的偏差略大一些, 特别是CNN 的SDII,偏差大于25%, 代表对降水值的预测非常不准
C'est le section 3.2, la comparaison dans des conditions non idéales, c'est à dire , on utilise des sorties de GCM pour la prédiction.
on peux voir tous les résultats présentent un biais plus grand par rapport à la situation idéale, en particulier Le SDII du CNN, avec un biais de plus de 25%, ce qui signifie que la prédiction des valeurs de précipitations est pas très précise.
再就是极端降水的情况下, GLM倾向于低估极端降水, CNN倾向于高估极端降水, APRF结果更好
dans le cas de précipitations extrêmes, le GLM a tendance à sous estimer , CNN a tendance à surestimer, le résultat de APRF est mieux
c'est le resultat de DW WW, dry days to wet day and wet day to wet day. on peux voir ces biais sont grand, c'est pourquoi ils ont proposé un amélioration de APRF
c'est le section 3.3, on utilise également des sorties de GCM pour prédire, mais c'est les données futurs, et parce que on a pas les données d'observations futur, donc nous pouvons pas dessiner un graphique de biais comme avant
donc il a présenté scatter plot, 后续待补充
apres c'est l'implémentation, c'est à dire mon travail de reproduction
c'est les données réanalysé x predictor, ils ont 20 predictors, et c'est le nombre de jours, c'est la dimension de grille, latitude et longitude, donc au total on a 600 grilles, c'est ça.
on a également les informations sur la date, et les coordonnées des grilles
c'est y les données d'observations, il y a 86 station, on supprime 3 station qui contient missing data
et l'intensité de précipitation, le minimum est 0mm le jour sec, le Maximum est 321mm, le précipitation extrême.
c'est les informations sur la validations croisé, on a 24 ans pour training et 6 ans pour testing
c'est l'idée de régional PCA, vous aves déjà compris donc je le passe rapidement
la fonction prepareData, c'est sont processus, et la façon d'appel, x y et 95% et les predictors.
et les sorties
c'est la fonction de prepareNewData, qui va mapper de nouvelles données ver principal component space.
son processus, et la façon d'appel
c'est la fonction de modélisation, le modèle d'occurrence, utilise la distribution de Bernoulli pour déterminer s'il va pleuvoir,le modèle d'intensité,utilise la distribution de gamma pour prédire l'intensité des précipitations.
这是进行PCA前后的维度对比,这就是为什么我们需要进行PCA 以及,为什么需要进行区域PCA。
c'est la comparaison des dimension avant et apres PCA , c'est pourquoi on a besoins de faire PCA et pourquoi nous avons besoin de faire une PCA régionale.
如果不进行PCA的话,我们同时要对这么多数据进行模型的训练,计算量太大,我尝试过,程序会直接报错,说数据维度超过函数处理的上限
si on fait pas PCA, alors on doit entrainer un modèle avec autant de données, le charge de calcul est trop grand, j'ai essayé, le programme a directement signalé une erreur: la dimension des données dépassaient la limite de traitement de la fonction.
另一方面,如果进行全局PCA的话,意味着我们要同时对这么多数据做一次PCA操作,这在代码中需要花费一个小时的时间,但是区域PCA把他分成八次小PCA来做,总共只需要五分钟
d'autre part, si l'on effectue PCA global, ce la signifie que on doit effectuer l'opération PCA avec autant de données en meme temps, ca prend 1h dans le code, mais si on le divise en huit petite PCA à faire, il ne prend que 5 minute
而且这这是从计算量大角度来讲,区域PCA还可以更好的利用站点周围的信息,blabla
de plus , c'ets le point de vue du charge de calcul, ne mentionne plus la PCA régional peux mieux utiliser les informations autour de station, blabla
这是函数最后的伪代码流程,先进行数据处理,然后开始交叉验证循环,划分数据,进行区域PCA,然后对每个站点训练GLM模型,最后得到三个参数 p alpha beta,这样就可以描述伯努利伽马混合分布,然后对这个分布采样500次用以计算分布指标。
c'est le processus de pseudo code, on fait d'abord le traitement des données, et puis commencer la boucle de validation croisée, diviser les données, effectuer PCA régionale, et apres , on entraine un modele de GLM pour chaque station, et a la fin on obtiens 3 paramètres p alpha beta, comme ça , nous pouvons décrire la distribution mixé de Bernoulli et gamma, et enfin , on échantillonne cette distribution 500 fois pour calculer les indicateurs de distribution.